
Using ODI with Git Versioning — Part 2: A Game of Tag
Last time I blogged about getting started with the new Git VCS functionality in Oracle Data Integrator (ODI) 12.2. Then, I promised to write a bit on integrating Git into the deployment process.
Firstly, a disclaimer. I used to work for a IT services company that also ran one of the largest ITIL training organizations in EMEA. In the traditions of “Eat your own dog food”, it was inevitable that the disciplines of release control and configuration management underpinned all we did. We also developed (in collaboration with other global IT companies) methodologies to bring the ‘software’ side of the house into a similar framework to the one used for ‘infrastructure’. Of course, this was not a simple drop-in of a process; developers have different needs from infrastructure deployment folk. From the deployment side of the house we need to document and create packages of artefacts to deploy (these may be scripts, binary files, ODI scenarios) and at the same time freeze a copy of the development source code so that developers and support staff have a code commit point to work from for subsequent development and bug-fix activities. Developers need more than that, they need to be able to save versions during the development process so that they protect the code they are developing from all kinds of mishap. Often the code that developers need to track in an SCM is way more than the deployed codebase, and the waters are muddied further when we consider commonplace processes such as continuous integration. Basically, it boils down to my expectations with Git-based development and deployment, and how those expectations are actually met in the SCM integration documented by Oracle when they introduced Subversion VCS to ODI.
Organizing your work
Although the Oracle ODI versioning documentation suggests that small teams can do their development in trunk, that is simply not the best way to approach this, for two reasons. Firstly, ODI’s Create New Version paradigm always saves and commits to the remote Git repository; it is far cleaner to develop in an isolated branch and have a Git release manager or deployment engineer managing the downstream SCM merge process. Secondly if we are using any automation based on Git commit hooks (such as continuous integration processes using Jenkins) it is sensible that we do this from a “clean” codebase and use the commit messages from the merge as the process trigger.
The other organizational question is where does everything sit in the environment? To help explain this I have created this simplified schematic:
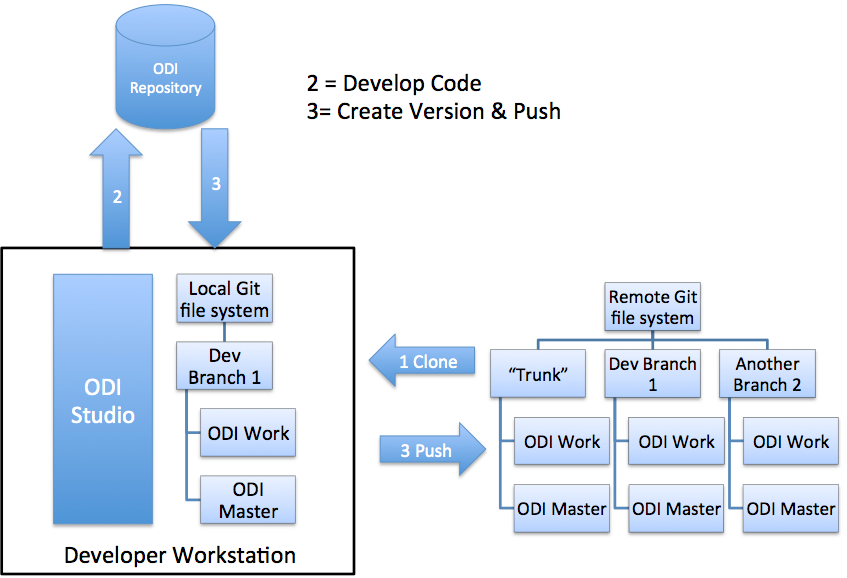
Schematic of relationship between ODI Repository, Developer Workstation and remote Git Repository
As you can see, there is a remote file system holding the whole Git repository. This remote Git repository may be at a hosting provider such as github.com, or it could be an in-house repository running on some git server. The developer clones a single branch from the remote repository to a local Git file system (usually) on the developer’s workstation. So far this is standard Git practice. ODI adds to this by including a database-hosted ODI repository. Optionally, the Git file systems can seed the ODI repository, and of course the ODI repository sends changes to Git (local and remote repositories) whenever we create a new version.
All sounds simple. The potential “gotcha” is that ODI only supports a single set of objects in the work and master repositories. As an example: I am developing some new mappings in my “SalesDevJan2017” branch and my colleague, Lisa, is working in her “CustomerDevMar2017” branch. Both of our branches contain some datastores and mappings that relate to customer; what if Lisa adds some new attributes to the customer table that won’t go live until the quarter after my changes? As soon as I version all changed objects there is a risk that my branch will contain code / objects that haven’t been finalized yet.
We have four basic options:
- Use ODI as the master codebase and Git as an out-of-line code store. This is pretty much what we did in ODI 12.1 (and earlier) days; create XML exports of the objects and store in a file system. We get the benefit of version restore, but little else. I just don’t like this, ODI is never going to be the sole source of the artefacts we need to version in a project (think DDL, documentation, report definitions etc). Git should be our corporate repository of source, not a cluster of multi-master islands of code.
- Create a branch for each sprint (if we are agile) and have all developers work in the same branch. Of course we still have potential problems for work that takes longer than a single sprint.
- Create an ODI WORK repository for each developer and develop in individual branches. This gives great isolation for all the design components, but still requires shared components in the security, topology parts of the MASTER repository.
- Give each developer his or her own ODI repository database and a Git branch to work in. This gives us maximum isolation of development. Obviously, there may be a potential license cost for all of those repository databases however we can consider ways to mitigate this such as named user licensing on development / test platforms or by running multiple ODI repositories on the same platform, either as separate DB instances or as multiple schemas within one database.
The flow for option 4 could be:
- Clone the master code line to create a new branch
- Populate the ODI work and master repositories from the branch
- Develop ODI code and version when necessary
- Version the ODI repository
- Merge the branch back in to the master

Example flow for development
Deployments
Here my release management gene kicks in: I want to move source control away from code releases. True, there is always a need to tie code at a point in time to the executable version of released code but we don’t really want to clutter our code repository with a large number of executables that are not required. We also need a way to handle the executables away from the code; there is no place for source code on any platform other than development (well maybe hot-fix, but that is really just a special case of a git branch). I also want a way to back-out a release if things go wrong.
In ODI terms, I will need to deploy the scenarios and loadplans generated from ODI. I also need to deploy any non-ODI configuration scripting, this will include shell scripts, DDL files, data seeding scripts etc. The non-ODI scripts are fairly straight forward, we just create additional directories in our branch to hold the scripts and manage that though a Git client or web interface. For the ODI materials we can use another ODI 12.2 feature, the deployment archive.
In simple terms, the deployment archive is a pair of zip files, one containing the XML source files, the other containing the executable scenarios and load plans. It is this executable archive that we need to deploy to our testing and production environments. The source zip should not contain anything we do not already have in SCM, but it is nice to have a single file that ties to the released executables. In fact the deployment archive is a tad more sophisticated than this, we create ‘Initial’ deployments (all content) or ‘patch’ deployments (just changes to apply) where we can also generate ‘rollback’ archives to allow us to revert patches.
The deployment archive functionality is linked to the concept of ‘Tags’ in SCM. Git tags are not the same as subversion labels, but for our ODI deployments this is not too relevant. We create a tag in git from ODI studio and then use this tag to identify all of the objects to include in the deployment archive. ODI has a concept of a partial tag— this is of course not a real git term. Think of a partial tag as a user generated list of objects, the editor for a partial tag is quite similar to the one for smart exports. However I think it is better to use a full tag, that is all the tracked objects.
Once our tag is in git we can use create deployment archive from VCS label to generate the archives. This gives us a set of zip file we can add to git and then deploy. Better yet we can use the ODI scripting SDK to develop an automated process to rollout code to the test, UAT, production as part of a CI workflow.
11 Responses to Using ODI with Git Versioning — Part 2: A Game of Tag