
One of the features of Oracle Data Integrator that sets it apart from other data integration tools is the use of Knowledge Modules to define how parts of the data integration process occur. The developer creates a data load mapping from sources, joins, filters and targets (and in ODI 12 even more components are available). However, it is the knowledge modules that have responsibility for describing the code that will be generated at execution time. The same logical design could be coded as a bulk truncate-insert with one set of KMs and as an incremental update using another.
True, there are many out-of-the-box KMs, or KMs available for download from the ODI Exchange, but at some point most developers will wish to customize an existing KM or create a new piece of functionality for their ODI processes. Typically we work with Integration KMs (IKM) and Load KMs (LKM) as these do much of the ODI heavy lifting.
Writing a KM sounds complex but the process is not too daunting. Under the covers there is a lot of similarity between writing an ODI procedure and a KM. Both can have multiple steps, both can use a variety of technologies, both are able to execute code steps on the “source” and / or “target”; the step editors are very similar. The key difference is that we write a procedure to do some “one-off” piece of functionality such as update a control table or SFTP some files to a remote platform; the KM however provides a more generic process that can use ODI metadata to describe the data structures being manipulated.
Here at Red Pill Analytics we have already produced some IKMs for our own set-based + analytic function approach to loading and maintaining Slowly Changing Dimensions. We have created custom versions of this KM to support Oracle 11g (and higher) and the latest MS SQL Server versions (some SQL syntax, keywords and functions differ between MSSQL and Oracle hence the need for two versions). Similarly, we have created a bulk incremental update IKM for MSSQL, using the “EXCEPT” set operator (EXCEPT is MSSQL’s equivalent of Oracle’s MINUS) to identify changes between the work table and the target. More recently we have created custom KMs for cloud-hosted databases, the latest being the one we wrote for the Snowflake Elastic Data Warehouse service.
Our first Snowflake KM was a special RKM to reverse engineer an existing Snowflake database into the ODI data stores and models. This KM utilizes Snowflake’s information schema to retrieve table design. Our second Snowflake KM was an IKM to bulk load a Snowflake target table from a SQL source.
Although it is quite possible to load most cloud databases using standard SQL insert commands executed through a JDBC driver, it is preferable to adopt a different approach for moving large numbers of rows to cloud hosted platforms such as Amazon Redshift or Snowflake. For this type of use we should extract our data to file and then use platform specific file load commands to populate our target table. This approach is equally valid for bulk loading relational databases such as Oracle and is especially recommended for Exadata.
Rather than give the exact code we use, I will outline the steps we might take to populate a cloud hosted data warehouse platform — in fact the exact step syntax will vary with database vendor and connection security methods.
- Unload the results of the source query to a file. It is most likely that we would use a character separated format such as CSV, but we could use some schema encoded format like JSON or XML. However, for most use cases simplicity is the best starting point, so go with CSV.
- Compress the output file: there are two reasons for this — smaller files are quicker to upload; and some cloud vendors charge by the byte transferred or stored.
- Upload the file. This is one of the highly platform specific calls. Loading an S3 bucket using a java API will not be the same as FTP, nor is the same as a native Snowflake “put” command, nor is the same as… well, you get the picture.
- Load the target table from the uploaded file. We may not need to uncompress the file first since many vendors (including Snowflake) support unzipping on the fly during table load.
We do have a couple of Red Pill Analytics “secret sauce” steps in our IKM (the Jython task shown in the editor screenshot), but the four steps above are basically it!
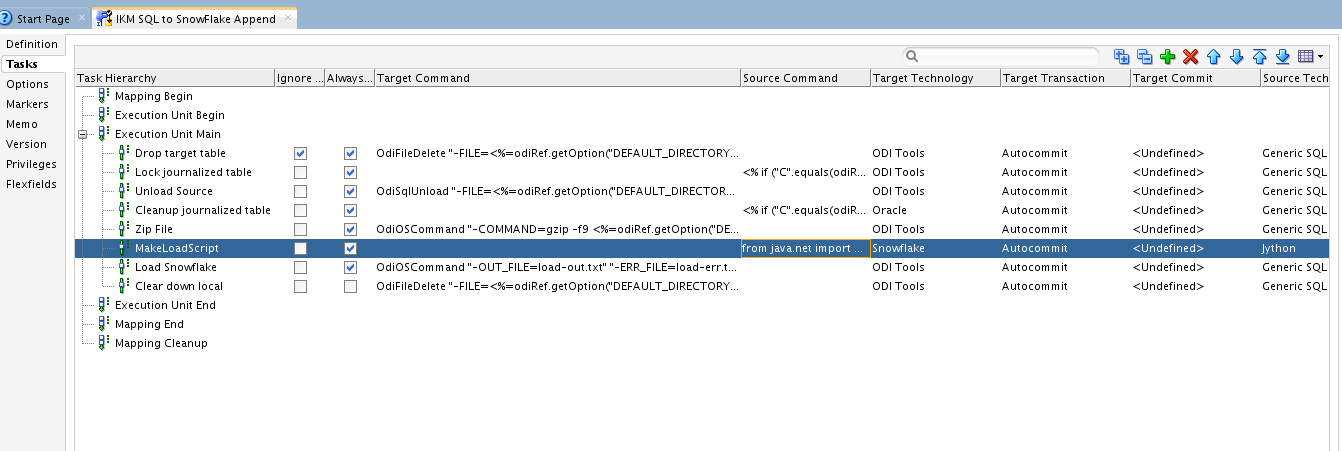
The first step in any KM development is to look at the available KMs to see if any of them would be a useful base to work from; for example a generic SQL to file IKM may already do some of the actions we need for a file based load. If we find a suitable base KM we can clone it and start work on editing the copy. We look at the steps we have to undertake and decide how much of the current code we can reuse, and how much is net-new. This is potentially the hard part as we have to weigh up technology choices for the various methods available. With the load to Snowflake I had choices such as:
- do I upload the file through a S3 java API in a jython step in my KM?
- do I raise an OS command to upload a file S3?
- do I raise an OS command to natively load Snowflake?
- do I use a web service?
Each option will have its own positive and negative points, for example can I put any required .JAR files on my ODI agent machine? How do I keep passwords secure? Do I have the code skills in java / Jython / Groovy to code what I want or am I better with shell script? Answer these questions and you on your way to creating your first ODI KMs.