
In my last post, I discussed Snowflake’s unique cloud offering, and how to get it connected to OBIEE. In this post, I’ll give a brief overview of what Snowflake’s Time Travel feature is, how to use it from a query perspective, and how to integrate this feature into OBIEE.
The Time Travel Feature
This is part of the Snowflake Fast Clone tech suite, a general Copy-on-WriteTechnology that includes Time Travel — querying data within a particular window of time. Simply put, those actions are querying, cloning, and restoring data that is found in tables, schemas or even entire databases that may have been updated or deleted. These Time Travel actions are executed as extensions to SQL with the AT, BEFORE, and UNDROP clauses, and can be executed within the data retention period. Speaking of which, the standard retention period is 24 hours and comes enabled automatically. Those with an enterprise level account can set data retention periods up to 90 days.
Testing the Theory with SQL
I’ll be editing some demo data within Snowflake for this example, but in a “real life” scenario, you may have writes being executed against tables that you could try to exclude from your result set. First things first then. Connect to your warehouse (as I’ve said previously, I’m a fan of using SQL Workbench/J with Snowflake), and take care of the essentials — resume and set your warehouse, and designate which database you’d like to use. Also, set the data retention time on the table you are going to use. Remember, you can use the browser to do most of these tasks as well.
alter warehouse demo_wh resume; use warehouse demo_wh; use database tpch_db; alter table tpch_sf100.orders set data_retention_time_in_days=1;
I decided I would add just a few records for one customer to a table to illustrate how this works, so let’s query the orders table for a customer. I returned 16 rows from the query below.
select * from tech_sf100.orders where o_custkey = 4400869 order by o_orderkey asc;
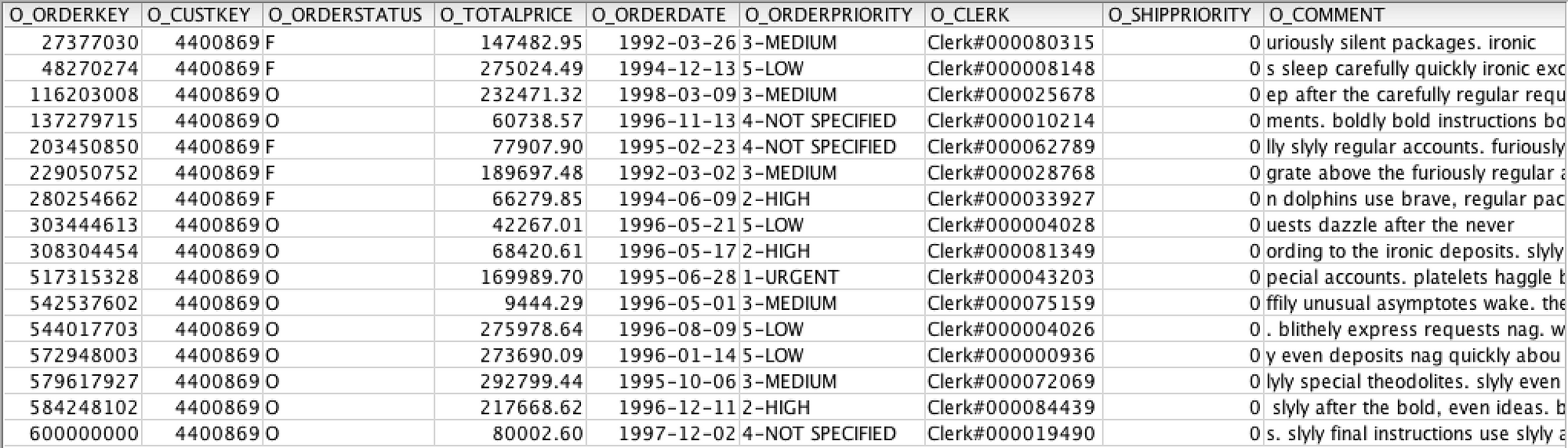
Looks great, right? Let’s create a few demo records to insert for this customer so we can test out Time Travel. Write your insert statements and execute them; mine are below.
insert into tpch_sf100.orders ( O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT) values ( 600000001, 4400869, ‘O’, 76543.2, ‘12/3/1997’, ‘4-NOT SPECIFIED’, ‘Clerk#000019490’, 0, ‘s. slyly final instructions use slyly after the fluffily regular’);
insert into tpch_sf100.orders ( O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT) values ( 600000002, 4400869, ‘O’, 34567.8, ‘12/4/1997’, ‘4-NOT SPECIFIED’, ‘Clerk#000019490’, 0, ‘s. slyly final instructions use slyly after the fluffily regular’);
Once the records have been inserted, run the query again. We should see 18 records in total, with the newest records at the bottom of the table.
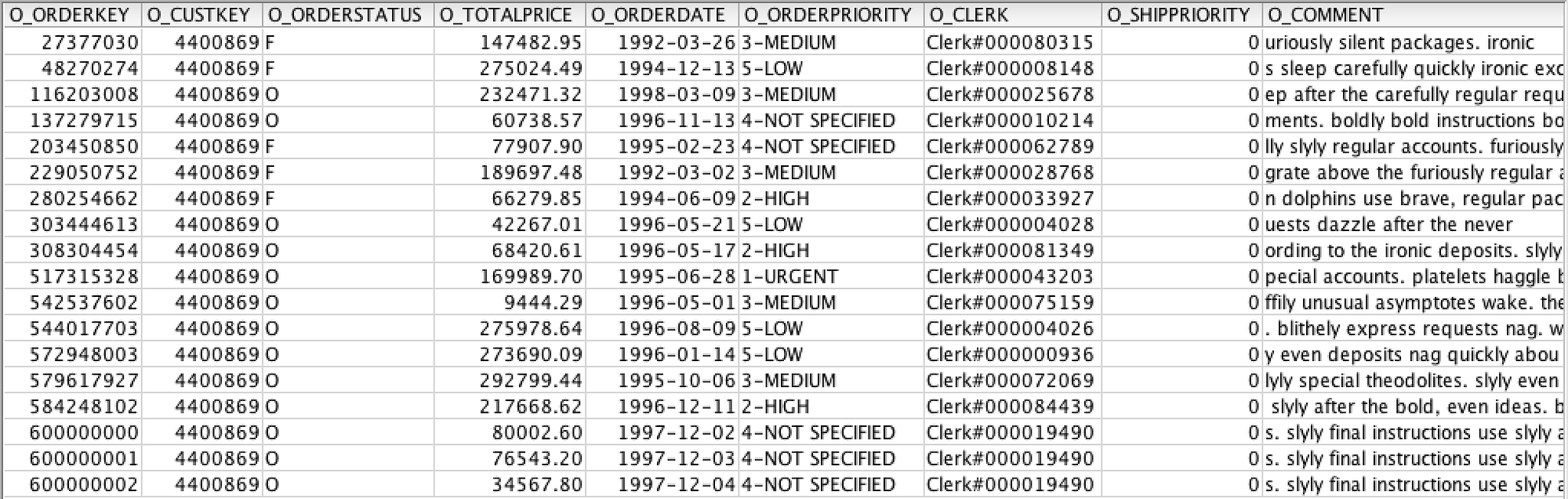
Now to test the Time Travel functionality. As discussed above, there are several ways to structure the query to activate the Time Travel feature. Let’s edit the query we used above and add the AT clause to the SQL.
select * from tech_sf100.orders at(offset => -60*5) where o_custkey = 4400869 order by o_orderkey asc;
The offset option will return results prior to the last 300 seconds (60 seconds times 5 minutes). If you run the query above, you should see the original 16 rows return. Now, let’s simulate that one of these records was mistakenly deleted, but we still wanted to query it. Delete one of the rows we inserted by running the script below.
delete from tpch_sf100.orders where o_orderkey = 600000001;
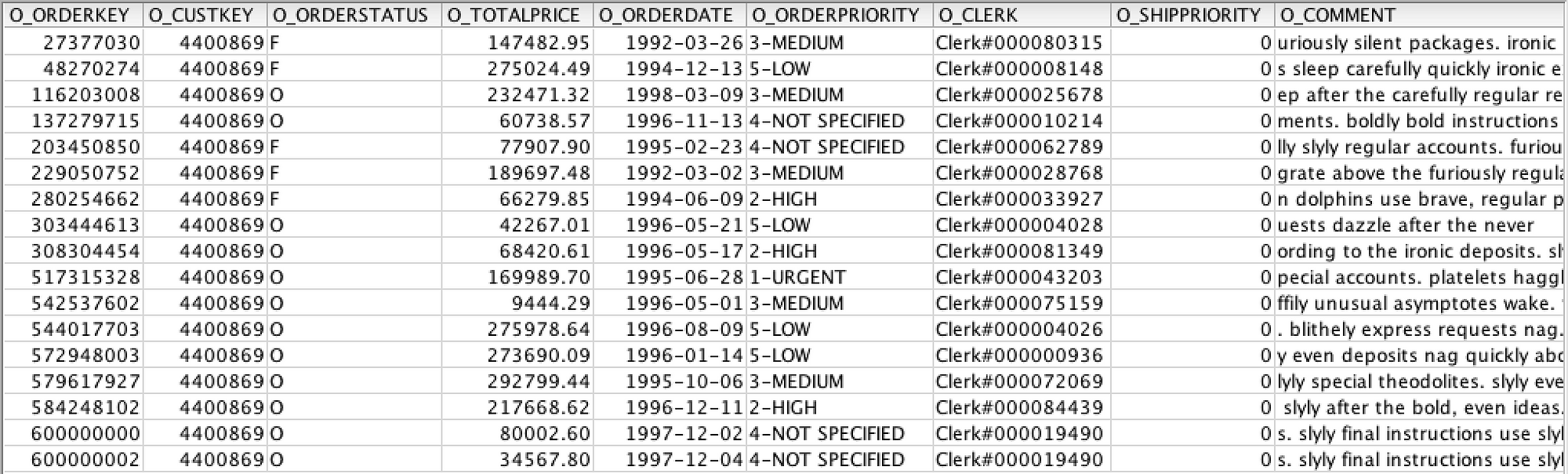
Now query the table without the AT clause. This will return 17 rows, with a jump from order 600000000 to 600000002. If you run the query with the AT clause, you’ll find that deleted record (o_orderkey = 600000001) is still in the data set. (You may need to change the interval of the offset to see this.) This is because Time Travel is capturing and retaining those records for the length of the data retention period, and adjusting the offset period adjusts the timeframe in which the query will look for the data.
Be careful using the AT or BEFORE clauses in your queries — if your TIMESTAMP, OFFSET or STATEMENT options fall outside of the retention period, the query will fail! Also, if using the AT of BEFORE clauses in a query with a join (in the real world, this would be most queries), the AT | BEFORE goes directly after the table name, as seen in the below example.
select
c.c_custkey customer_key
, c.c_name customer_name
, c.c_mktsegment market_segment
, c.c_phone phone_number
, c.c_acctbal account_balance
, o.o_orderkey order_key
, o.o_orderpriority order_priority
, o.o_orderdate order_date
, o.o_totalprice total_order_amount
from tpch_sf100.orders AT(offset => -60*5) o
, tpch_sf100.customer c
where o.o_custkey = c.c_custkey
and o_custkey = 4400869
and o_orderstatus = 'O'
order by o_orderpriority asc;Time Travel in OBIEE
As you may have seen from my last blog on Snowflake, I have an OBIEE instance up and running with Snowflake data. To test out the AT clause above, I created a new analysis, and headed over to the “Advanced” tab. I scrolled down to the “Advanced SQL Clauses” section and added my AT clause in the “FROM” section.

When I hit the “Apply SQL” button, I was greeted by a error for “Invalid SQL Identifier”. Hmm. Seems like OBIEE didn’t like that. And, to be honest, we should have expected this, right? As discussed in my last post, Snowflake is currently not a supported database type, so there may be some gaps in functionality. With a new feature like Time Travel, we may have to wait a few more OBIEE releases to get it to work from a straight analysis standpoint.
However, we can try to run an analysis as a Direct Database Request (you can read more about this functionality from Kevin and Greg). There are plently of OBIEE implementations that use this functionality, so, let’s do it. I navigated to the Direct Database Request, entered my Connection Pool information, pasted my query into the SQL Statement field, and hit “Validate SQL and Retrieve Columns”.
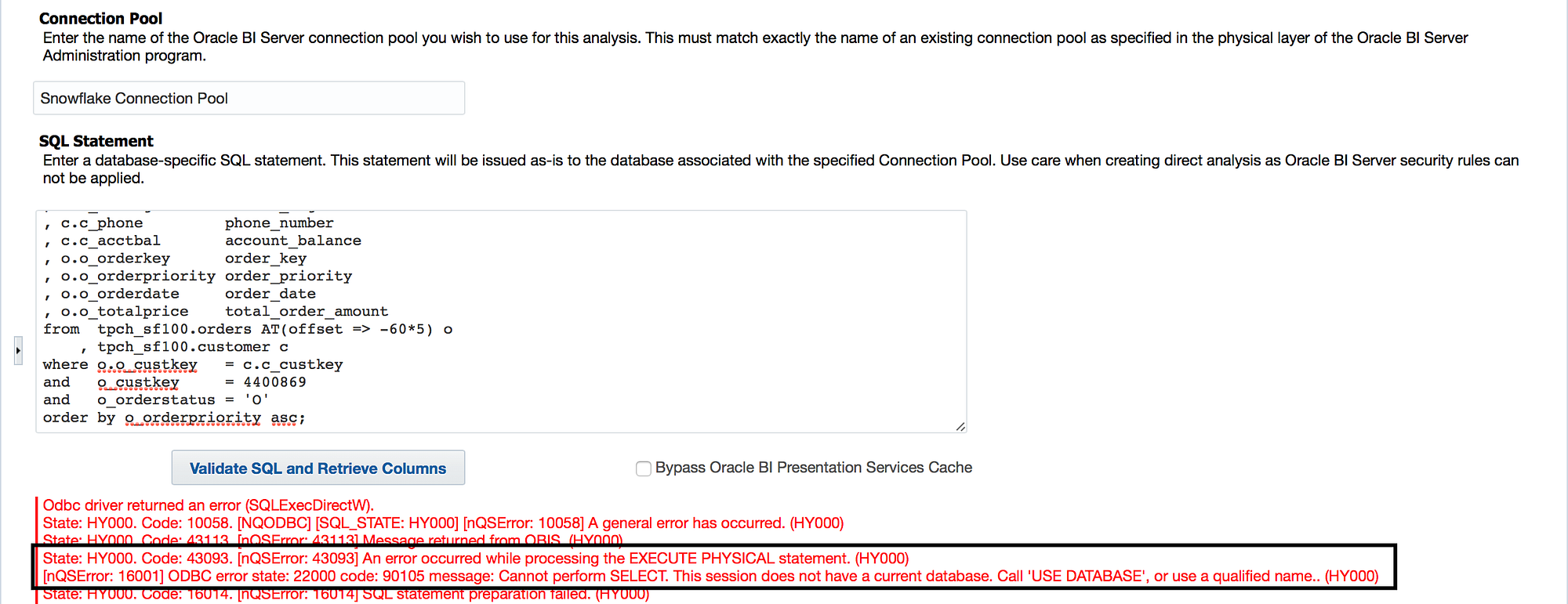
Again, I was greeted with an error, this time because the query did not inherit the database defined in the connection pool. And again, this should make sense, right? When using the browser or a query tool like SQL Workbench/J, we would have to explicitly define which warehouse and database we would want to use. Sometimes with greater flexibility comes the need for greater explicitness.
There are a few ways to work around this. I recommend setting a use database command in the Connection Scripts of the Connection Pool properties of the OBIEE repository (see my last blog post for how to accomplish this). If you don’t have access to the OBIEE repository, it is always possible to give the fully qualified name in the physical SQL.
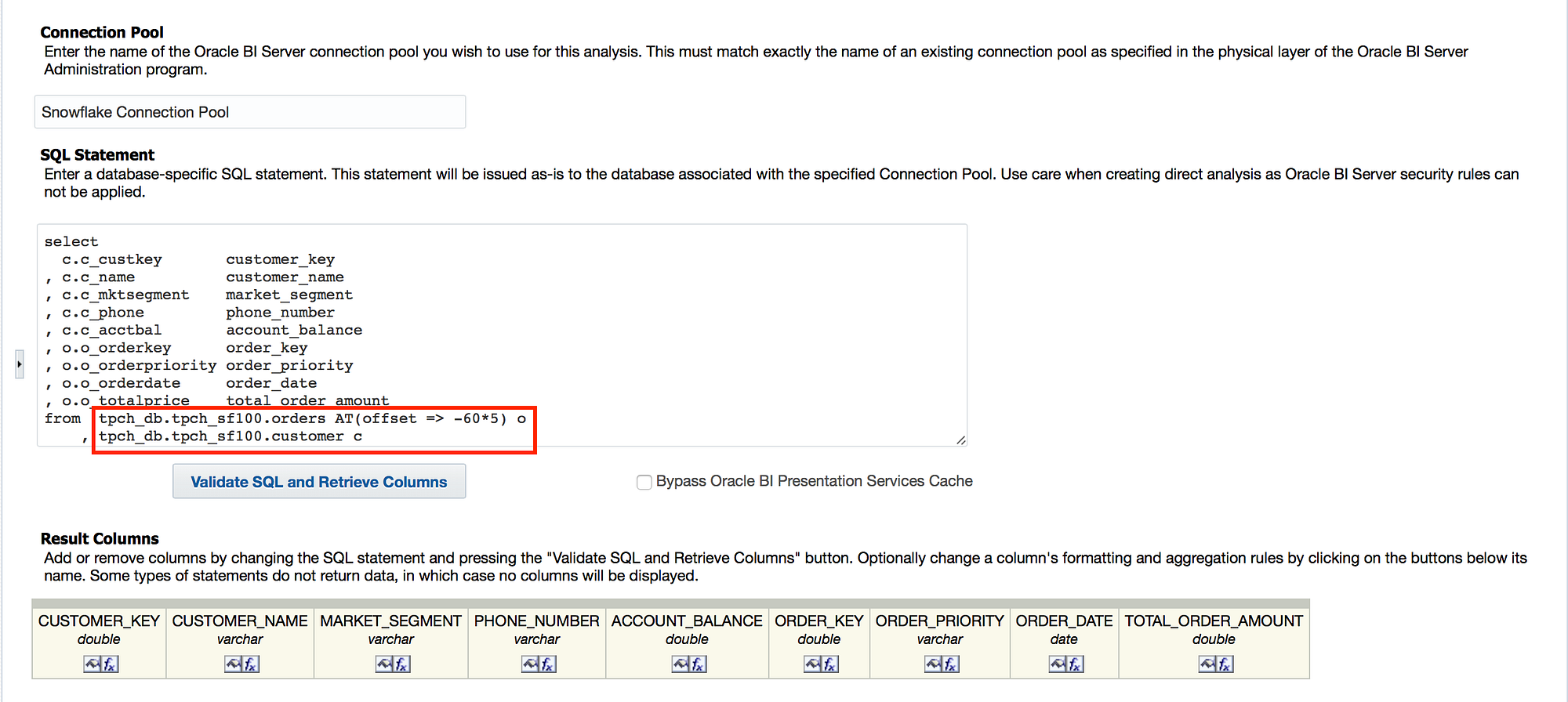
Once the fully qualified name has been defined, the SQL will validate, and will bring back the columns. From here you can play with all of the standard Direct Database Request features for presenting the data, including placing the analysis on a dashboard and prompting it with presentation variables.
OK… But Why Do It?
I know what you’re probably thinking: “Phil, why would anyone want to use this for reporting? This seems like it best left to the DBAs for damage control and loss prevention.” You may be right, and I’m definitely not suggesting that this become a tool in the tool shed that comes out frequently. But, I have a situation where I would have loved to have functionality like this.
In a previous life, I worked in the mortgage division of a large bank doing analytics for a team of loan underwriters and managers. Our underwriting process was based loosely on a First In, First Out (FIFO) basis; when our team got the loan files from the sales reps, they would be queued and prioritized based on several factors (loan amount, risk code, a variety of dates, loan class, etc.), and then assigned to the appropriate team member. The data flowed from the loan source system into a smaller analytics data mart, and from there, into a small, “under-the-desk” Access database. The data was passed into our “rogue” database as loans were updated in a web service form, but (in)conveniently, the timestamp nor date for of the update was available. With a feature like Time Travel, I could have set a retention period and only returned records from yesterday, two days ago, or even a week ago to help optimize which loan files to queue and prioritize.
Obviously, we didn’t have OBIEE during my tenure with that team, and we didn’t have Snowflake either. But, this could have implications in other operational settings if there are writes being executed against a table that is being queried. Maybe it is a supply chain issues to make sure all of the orders before a certain time were out the door. Maybe it’s an end of the month books balancing query to see the before and after numbers for the accounting team. Or maybe it is a Checkmate regression query to see test results before the last job. I’ll let your imagination run wild, but I do think that Time Travel has a place in the front-end tool shed.