
Anytime I’m speaking or presenting on either AgileAnalytics or continuous integration/continuous delivery, I usually insert a “Shadow IT Wants Your Soul!” slide complete with an image of Batman lurking in the shadows. For one… I’m a super-hero fan, and there’s always room for Batman. But secondly, and this time seriously: the folks setting the pace for analytics and BI delivery need to get with the program. The landscape has shifted; we no longer live in a time when IT can say “they’ll get it when they get it”. A simple Google search result of “cloud analytics platform” provides insight into the options that business users and middle managers now have for producing analytics with the swipe of a credit card. Instead of investing with IT to collaborate on the next round of reporting requirements, stakeholders are investing in cloud solutions and mid-market products, dumping data from all their different sources and uploading them as spreadsheets to these services. Why are business users shifting their focus away from IT organizations and instead to cloud analytics platforms? Well… because they can. This puts them in control of their own destiny… solutions by the business, for the business.
A Walk Down Memory Lane
The history of data warehousing tells us that the first data warehouse was likely built at ACNeilson in the early 1970s, where the phrase “data mart” was used internally to describe a retail sales decision support system. But the craft of modeling and loading separate systems for intelligent and analytical support emerged on a large scale in the 1980s. Bill Inmon published his article One Version of the Truth in 2004, but he didn’t coin the phrase: that rallying cry for the conformed, centrally managed data warehouse was already on the lips of C-level visionaries trying to pry their data out of stubborn transactional systems.

That paradigm was all about repeatability and control, and I can’t argue with those drivers. Watching a flock of stakeholders and consultants marching into a pow-wow with reports and decks all pointing to variably different numbers can be suffocating, and the data warehouses championed by Bill Inmon and Ralph Kimball provided foundational platforms that solved these problems and many others: performance, data quality, etc. So we scheduled nightly loads to our data warehouses, and ensured that everyone had the same clean, stale numbers.
How has this model changed over time? The first thing to go was the nightly batch window. Ralph Kimball first published Realtime Partitions in February, 2002, and this was the shot across the bow for what had become a somewhat data-stagnant industry. Data warehouses were opening up to casual, every-day users, and those every-day data requirements were less about high-level company growth and performance, and more about making minute decisions in realtime. And before we cast off the value of these minute decisions, we have to consider the effect that the aggregate of all those decisions can have on an organization, which, among other things, was championed in the book Competing on Analytics by Thomas Davenport in 2007.
Where are we now? Users demand rapid change… and they aren’t just describing access to realtime data. It’s now about rapid delivery of content… new ways to visualize their data, delivered iteratively and quickly. New dashboards and reports should be in the hands of users in days or weeks instead of months. How can BI developers, specifically those using Oracle Analytics products, design and model their process to meet these new demands? Well… I’m glad you asked.
I’m a little bit Development… I’m a little bit Operations
In case you haven’t read the memo… OBIEE out-of-the-box and development operations (or DevOps) are not a natural fit. The lifecycle management capabilities in OBIEE are indeed lacking (as with most other BI tools, it’s worth noting), but the degree depends a bit on how we develop with the tool, and which aspects of our methodology we are trying to supercharge. The general consensus seems to be that the metadata layer is our biggest bottleneck to rapidity… which is frustrating because, when done properly, the repository is the tool’s strongest capability. So let’s take a stab at fleshing out the two general approaches usually employed to slay this monster. In the spirit of gamification, I’ll be scoring each approach on two scales: ease of development, and ability to plug into automated operations, with a maximum of 3 points on each scale. Ladies and gentlemen… I give you the Brysonian BI DevOps Three-Point Scale.
Online Development on a Shared Server
In this scenario, we have our OBIEE metadata repository served-up in online mode on our development server. Developers either remote into the development server itself to use the Administration (Admin) Tool, or use a client install Admin Tool on their workstations to connect to OBIEE development in online mode. This approach has a lot of merit when it comes to development and delivering rapidly: our changes are immediately available to use for prototyping analyses and dashboards — which roughly equates to unit testing when considering the broader development landscape — and we have zero impedance to turning those changes over for proper completion of end-user requirements.
This approach loses ground when considering operations, as it’s almost impossible to build a process around shared online development. The check-in/check-out functionality in the Admin Tool is far from robust (we could almost label it as “flaky” in the absence of spin), and it produces a sort of free-for-all in a single development environment. Repository developers are constantly clobbering each other’s work, and dashboard developers are aiming at a moving target when trying to produce repeatable content while developing against a volatile metadata layer. We also have no version control of our “code” (metadata repository for the semantic layer… the web catalog for our analytics content.) Of course we can commit the metadata repository to a version control system at regular intervals… but that misses the point. Source control is about managing my changes and your changes granularly… seeing when new content was committed, and by whom.
Development: +2, Operations: 0
Offline Development using Multi-User Development (MUD)
I’ve often used the Matrix Reloaded architect scene when describing MUD, for two reasons. First… take a look at all those individual tube-style monitors, each displaying disparate scenes from the first two Matrix movies. How better to analogize a group of well-meaning developers forced to use dated tooling, trying to work in isolation, but somehow contributing to a larger whole? Second… the scene can be frustrating because it’s almost incomprehensible at first blush, much like MUD itself.
With MUD, an administrator defines a “master” repository… this is a binary metadata file that sits in a Windows share folder that is accessible to each developer’s workstation. That master repository has one or more MUD projects defined in it, and developers check-out the project they are interested in working on. Once the development is complete, it’s a simple publish of the project repository back to the MUD master repository.
Simple and effective, no? No. I tend to be somewhat vocal about my preference for not using MUD, but I will go down on record now: it’s better than doing nothing. MUD scores a few points on the operations side of the house (as you will see later), but not nearly enough. It passes our litmus test for version control, in that individual user changes are tracked in the MUD history binary file (.mhl) so that we can view, compare, rollback, etc. individual user changes. We can also convert that .mhl file to an XML file for committing back to a real source control system. However, it falters on the development scale for two reasons. First, it requires us to develop in offline mode… which makes it very difficult to unit test our changes, which I describe in some detail in a previous Medium article. But equally troublesome is the dialog box that developers are confronted with when they publish conflicted changes back to the master repository:
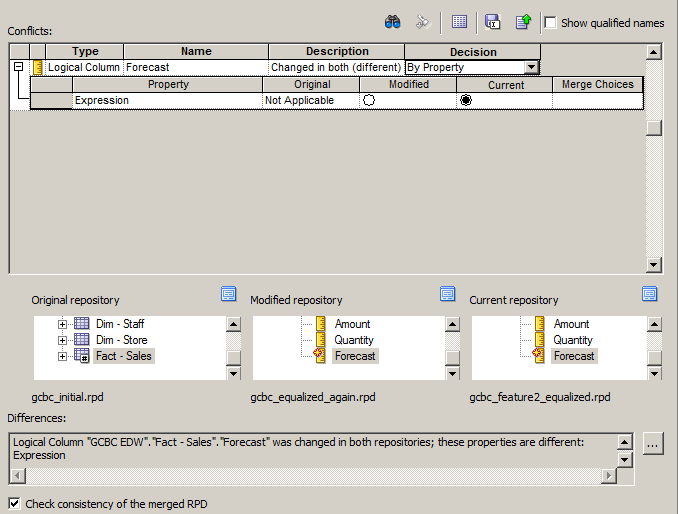
In this example, a change made to the Forecast measure conflicts with an already published change made to that same measure by a different developer. I don’t have an issue with the conflict… these inevitably happen. I do have an issue with the fact that this conflict has to be resolved during the publish phase by the developer herself.
Are individual developers guaranteed to be in a position to make the correct choice here? I would argue that they are not. Developers should develop… not manage the merging of branches… which is basically what this step in the process equates to in the world of source control management. Branch merging should be handled downstream of the development process as an aspect of code integration or release management. What self-respecting, confident metadata developer would ever accept the changes of another? Hey… it takes one to know one.
Development: 0, Operations: +1
It All Seems So Dated

To understand where we’re going, we have to understand where we’ve been, which is why I started this article with a bit of history around data warehousing in general. Equally important though is understanding where we are right now, and both development approaches in OBIEE feel dated. One of the things I’ve never understood about the lifecycle features in most BI tools is why the designers feel the need to roll their own source control and DevOps features. Instead of focusing on deeper integration with tools and processes that exist in the other 90% of development paradigms, BI vendors instead start with a clean palette and create something completely siloed and desperately alone.
In the subsequent articles in this series, we’ll take a look at how some of these other development paradigms approach DevOps — paying perhaps the closest attention to the world of Java development and other JVM languages. We’ll see how approaches such as continuous integration and continuous delivery play a part in rapid, iterative delivery, and how we can apply some of those approaches to the world of OBIEE development.