
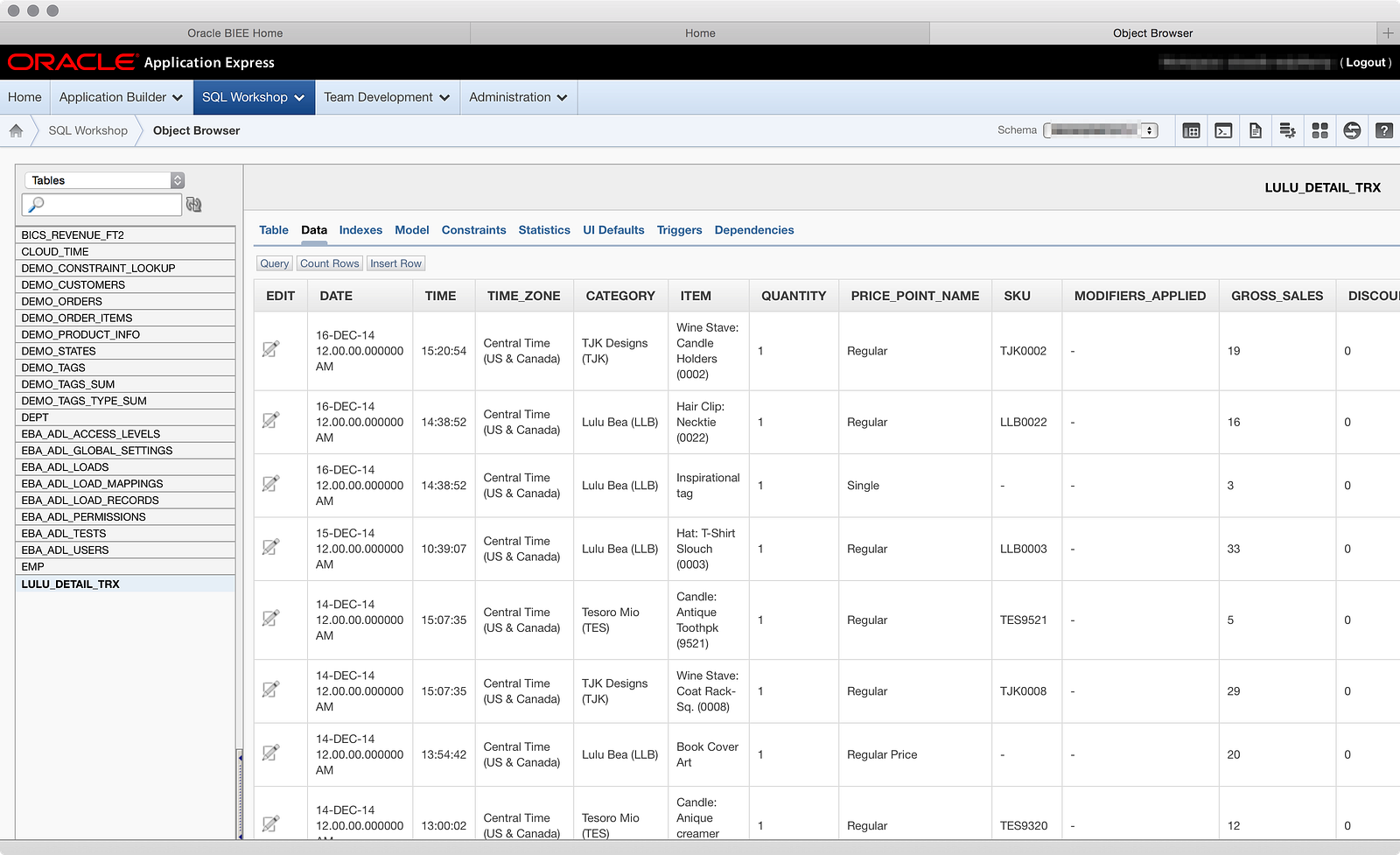
Welcome to Part 02 in a series of day-in-the-life (DITL) posts about using Oracle BI Cloud Service (BICS) in a real-world setting, with no filters and lots of mistakes! In Part 01, I wrote about loading my wife’s point-of-sale data from Square as the basis for an application I wanted to build. After a few challenges around the file and its structure, I was able to load the file into the schema that comes with BICS to get a working table with data, as shown below:
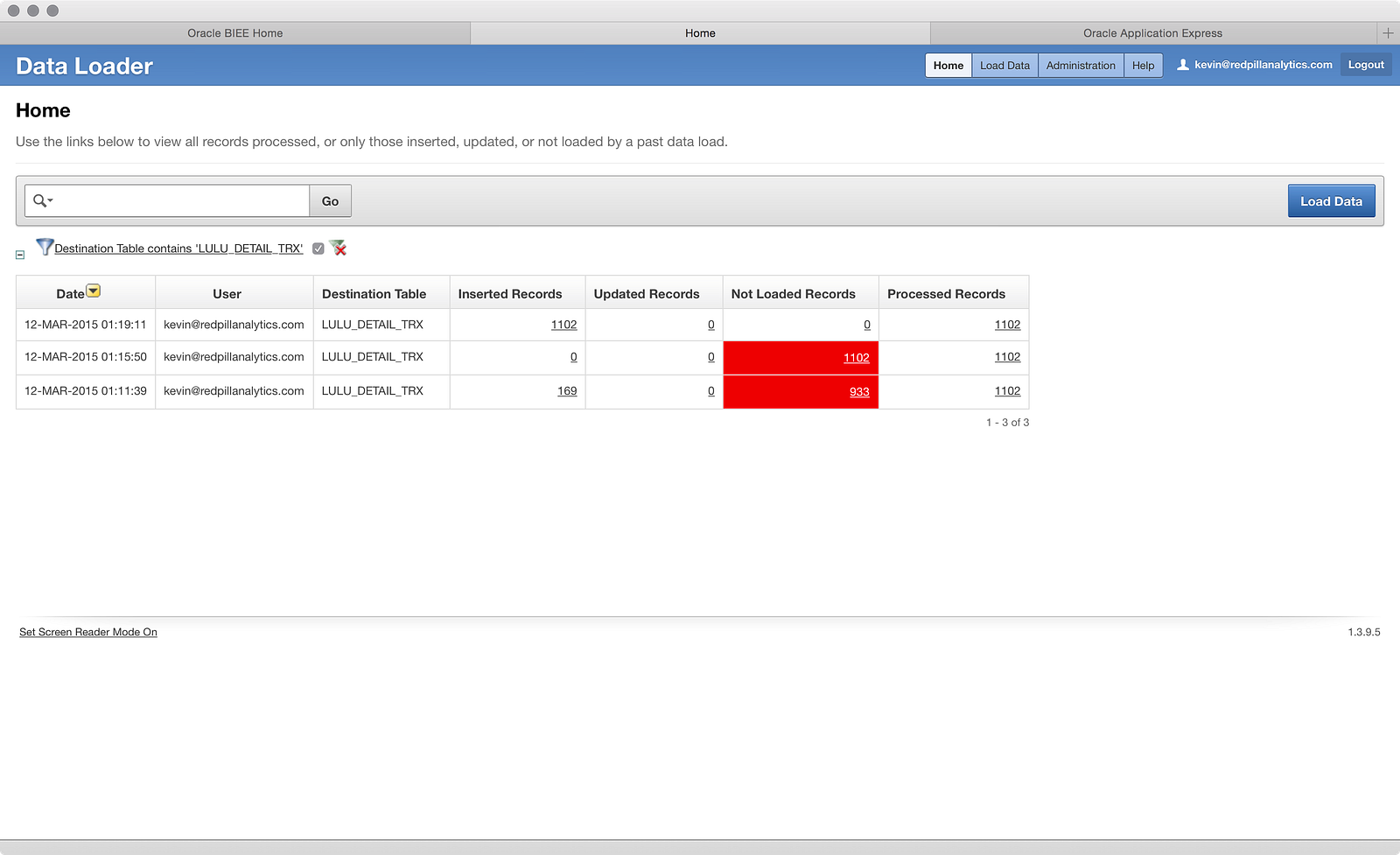
The next step in my process is to load more files into the same table, because as I mentioned in Part 01, Square only lets you export one year of data at a time. Since my wife has been in business for about 16 months now, I actually had to generate three files: one for 2014’s data (what I loaded in Part 01), Nov-Dec of 2013 (she opened in Nov 2013), and the first two full months of 2015. Going back to the data loader screen, you can see my previous two failed attempts and my successful attempt:
To load more data, I clicked the Load Data button and got the typical data screen:
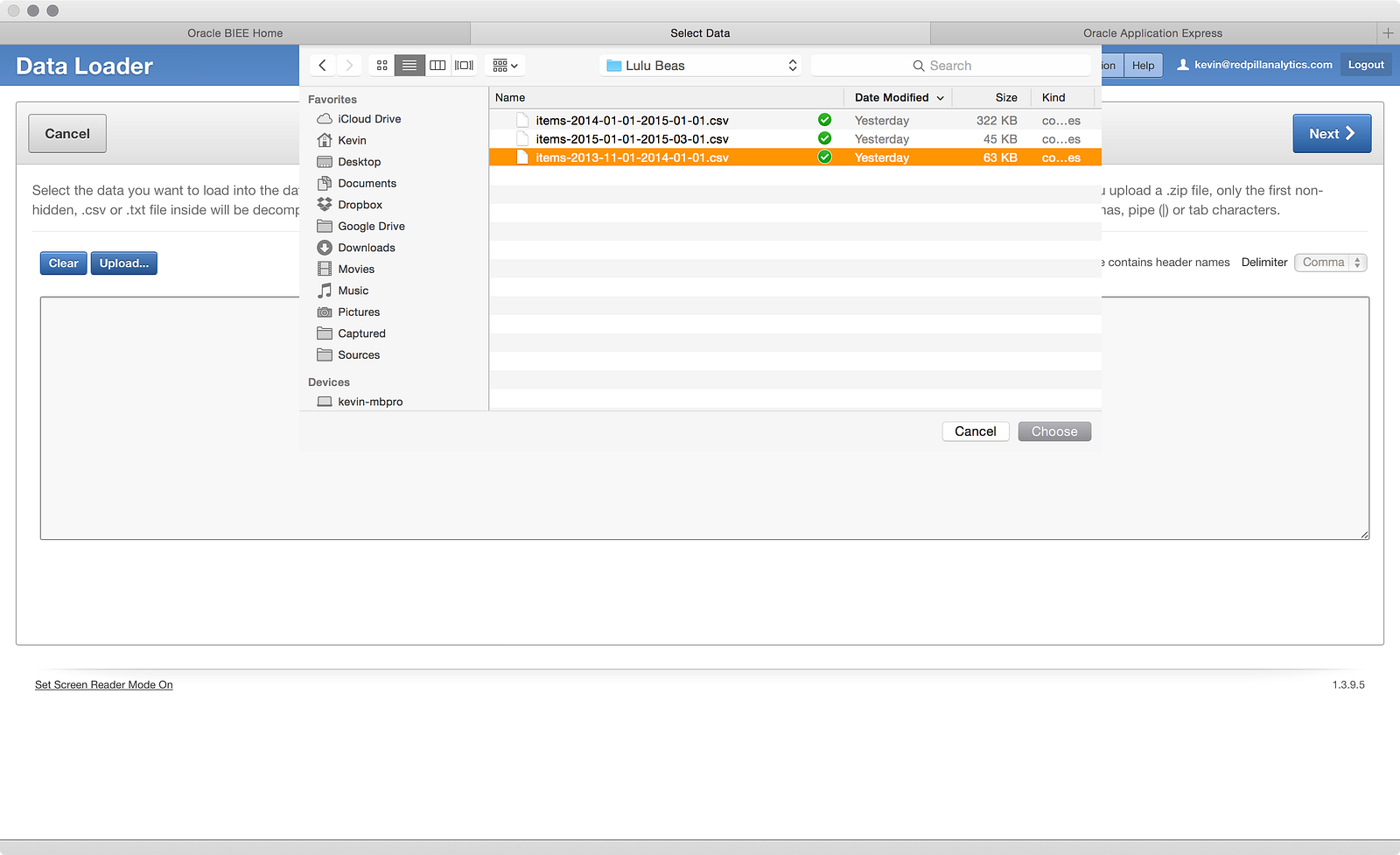
This time in my upload, I choose the 2013 file, as shown below:
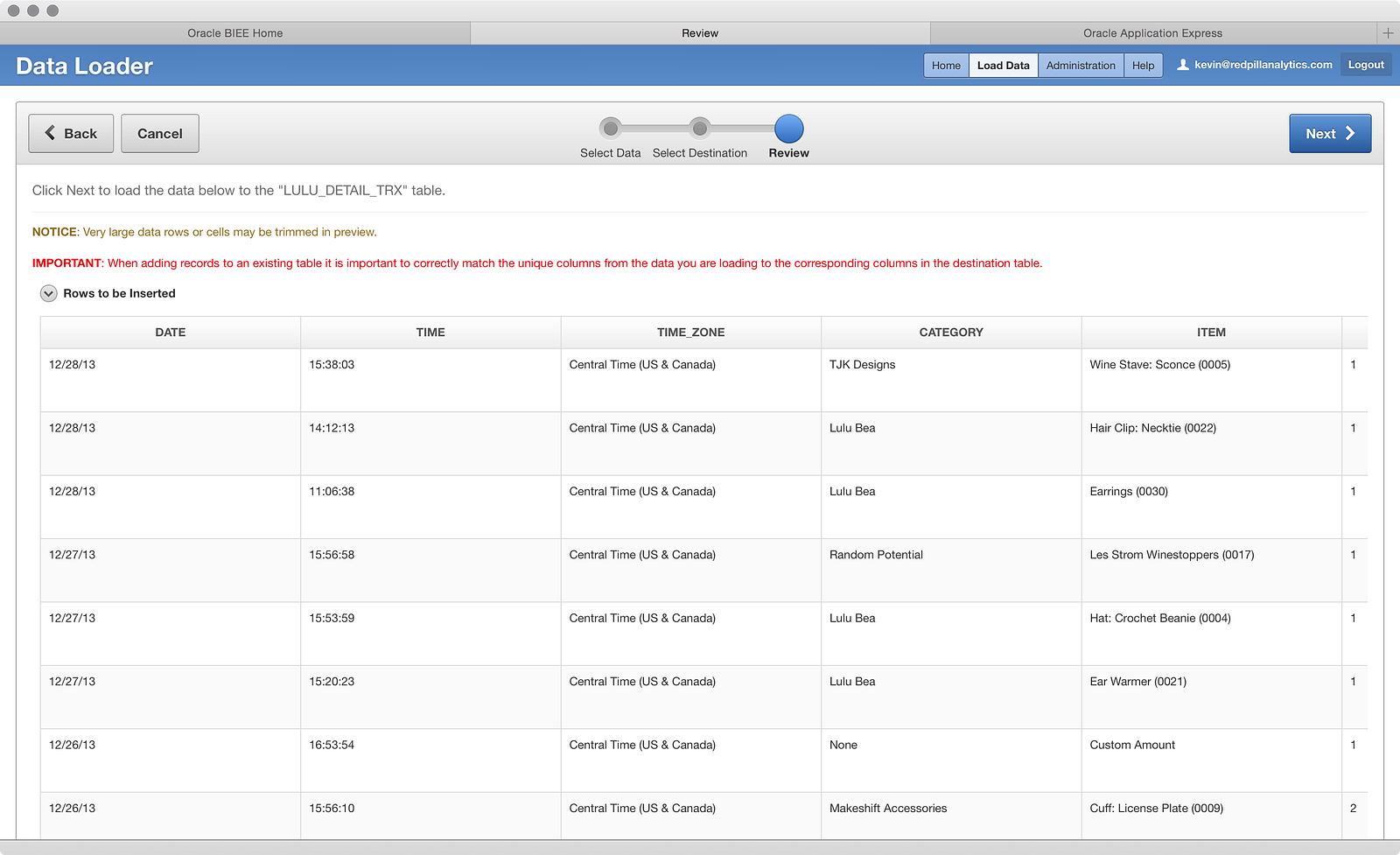
After clicking Next a few times, I get the screen where I can choose a new table or an existing table, and you can see in the table list that the LULU_DETAIL_TRX table is available.
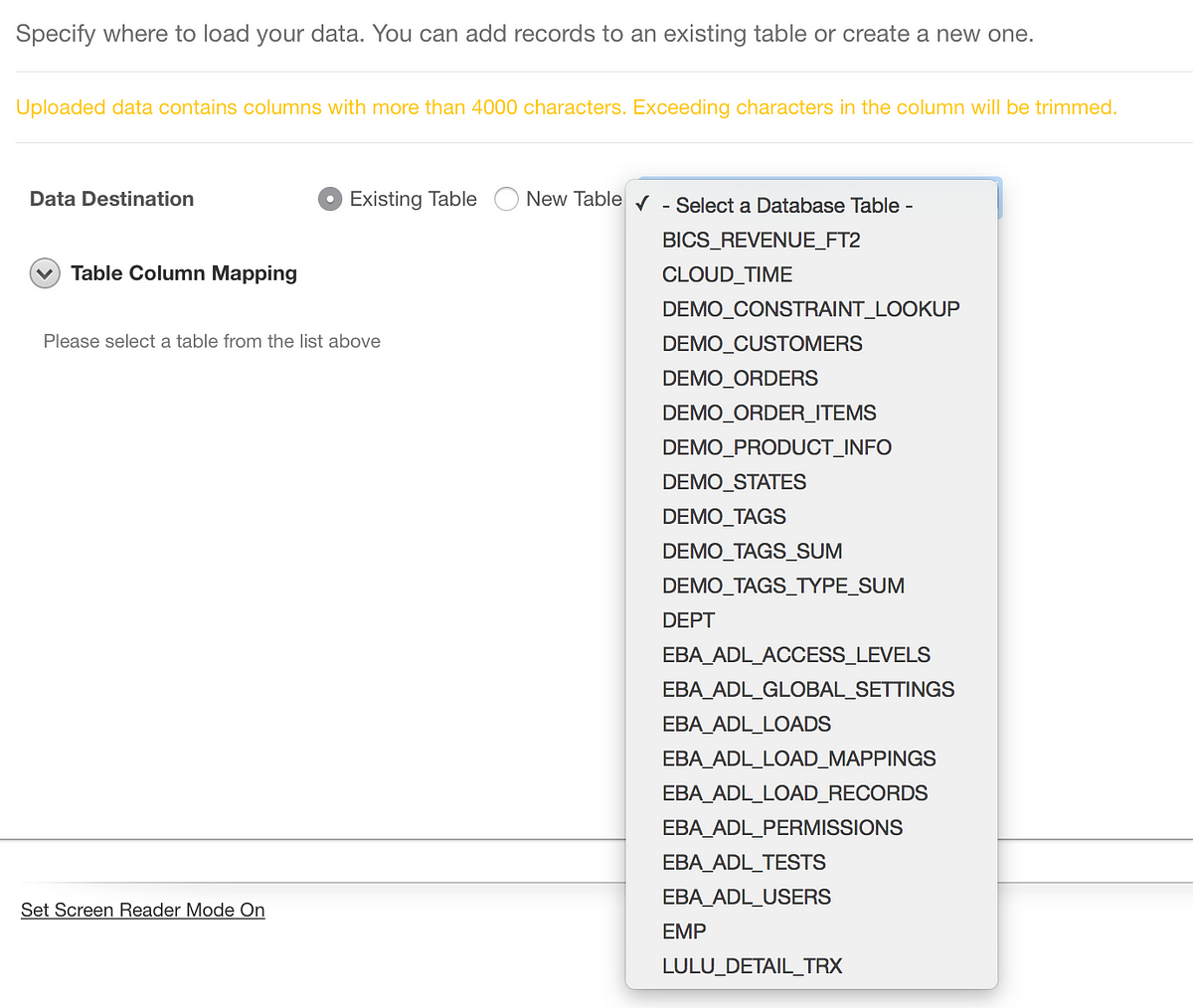
Now that we’ve selected a table to load into, you’ll notice the screen looks a little different than before:
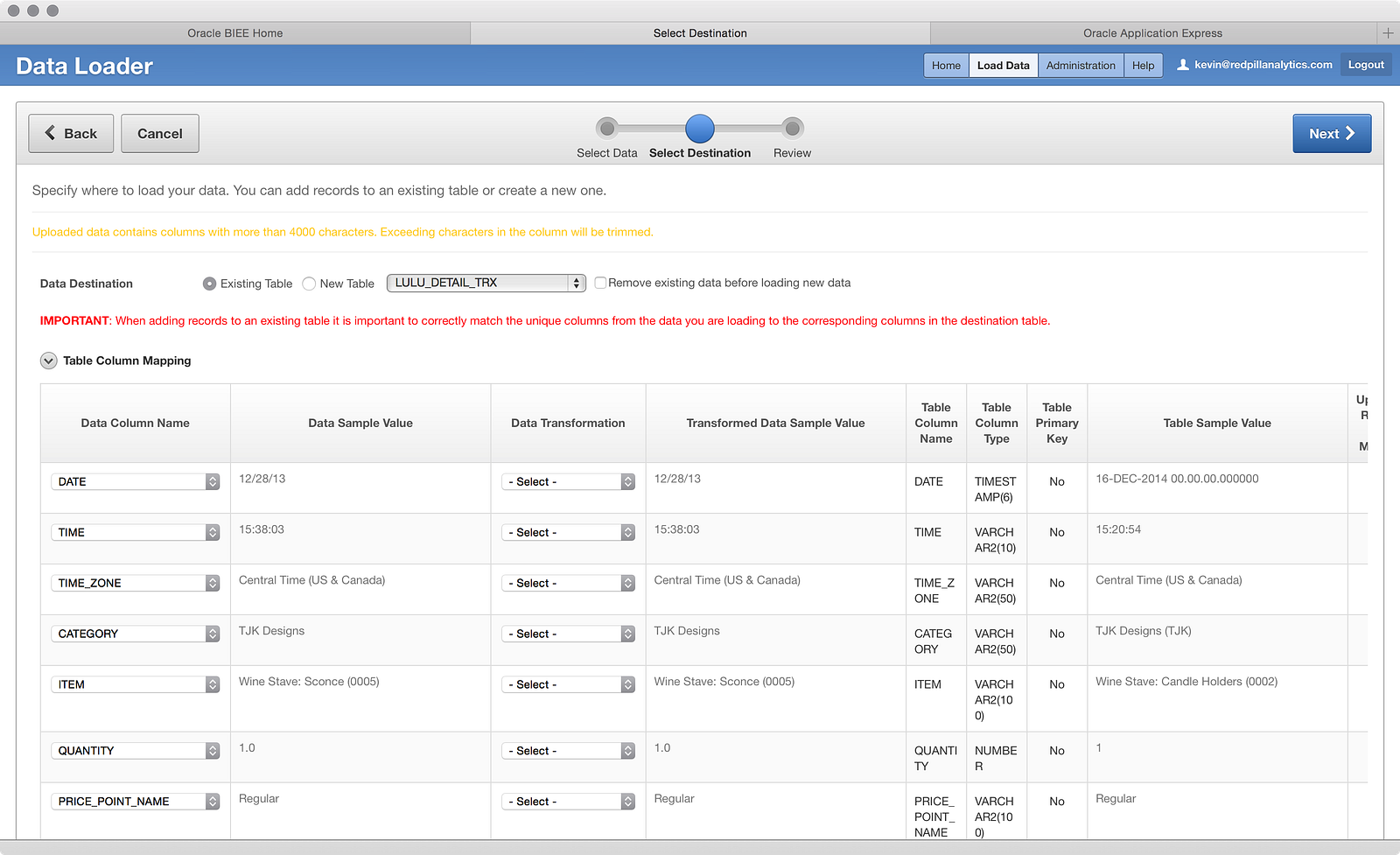
The first thing to point out is the big red IMPORTANT message that appears on your screen. Clearly Oracle wants you to pay attention to what you’re doing here, making sure to match the columns from the file to the table in the correct fashion. To that end, the Data Column Name is now a dropdown that can be configured, instead of a fixed value. Conversely, the Table Column Name and the Table Column Type fields are non-configurable, which makes sense since the table has already been created. However, what it does mean is that you won’t be changing data structures on-the-fly, so if you don’t size a column properly in the first place, you could run into challenges with other files later that might have larger text values in the same columns.
Scrolling down, we also see that the ‘NOTES’ column in the file (I didn’t remove it in this file like the one from Part 01) does not appear, but the dollar value columns are still formatted as text:
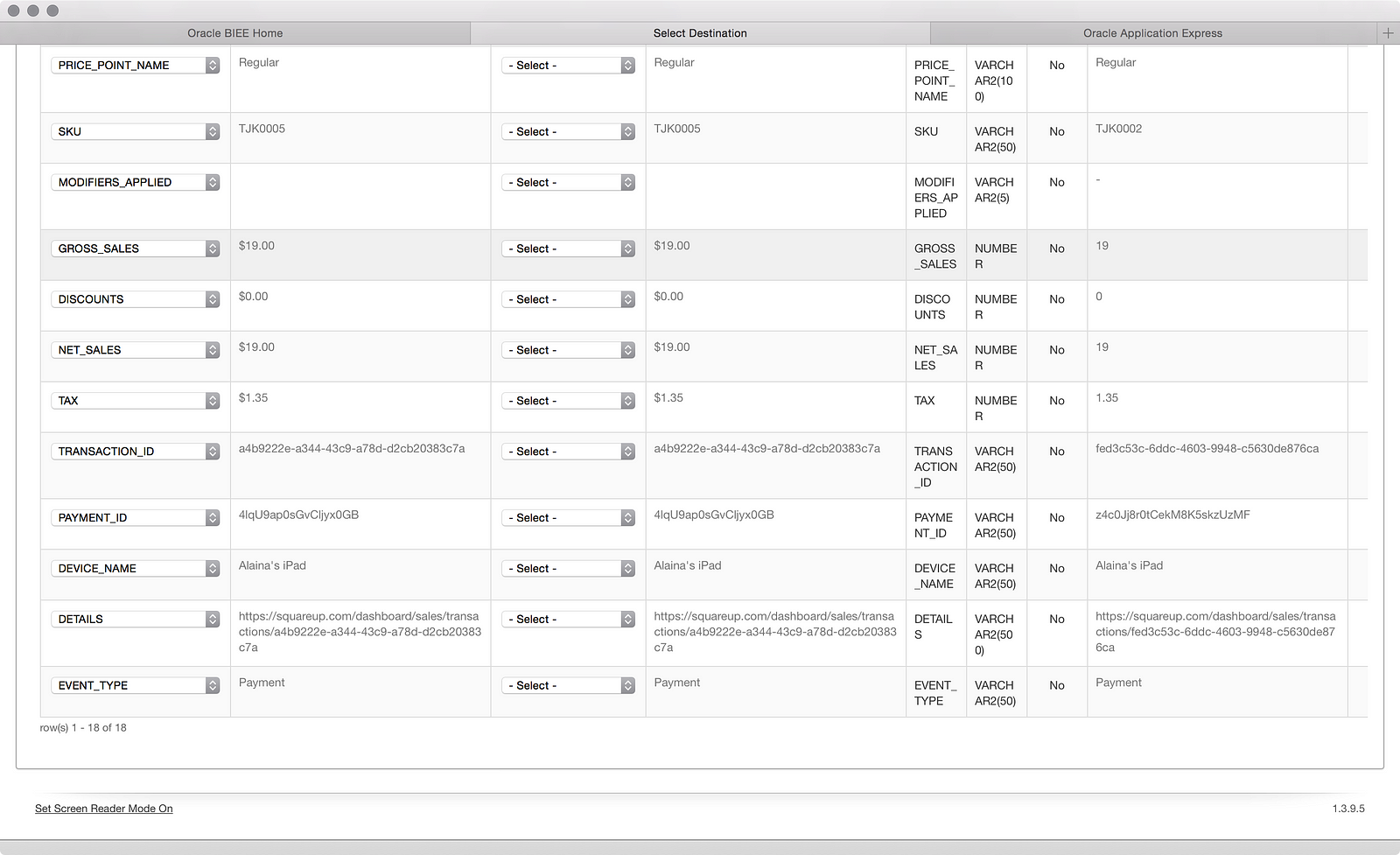
Making the simple edit as shown in Part 01 fixes that:
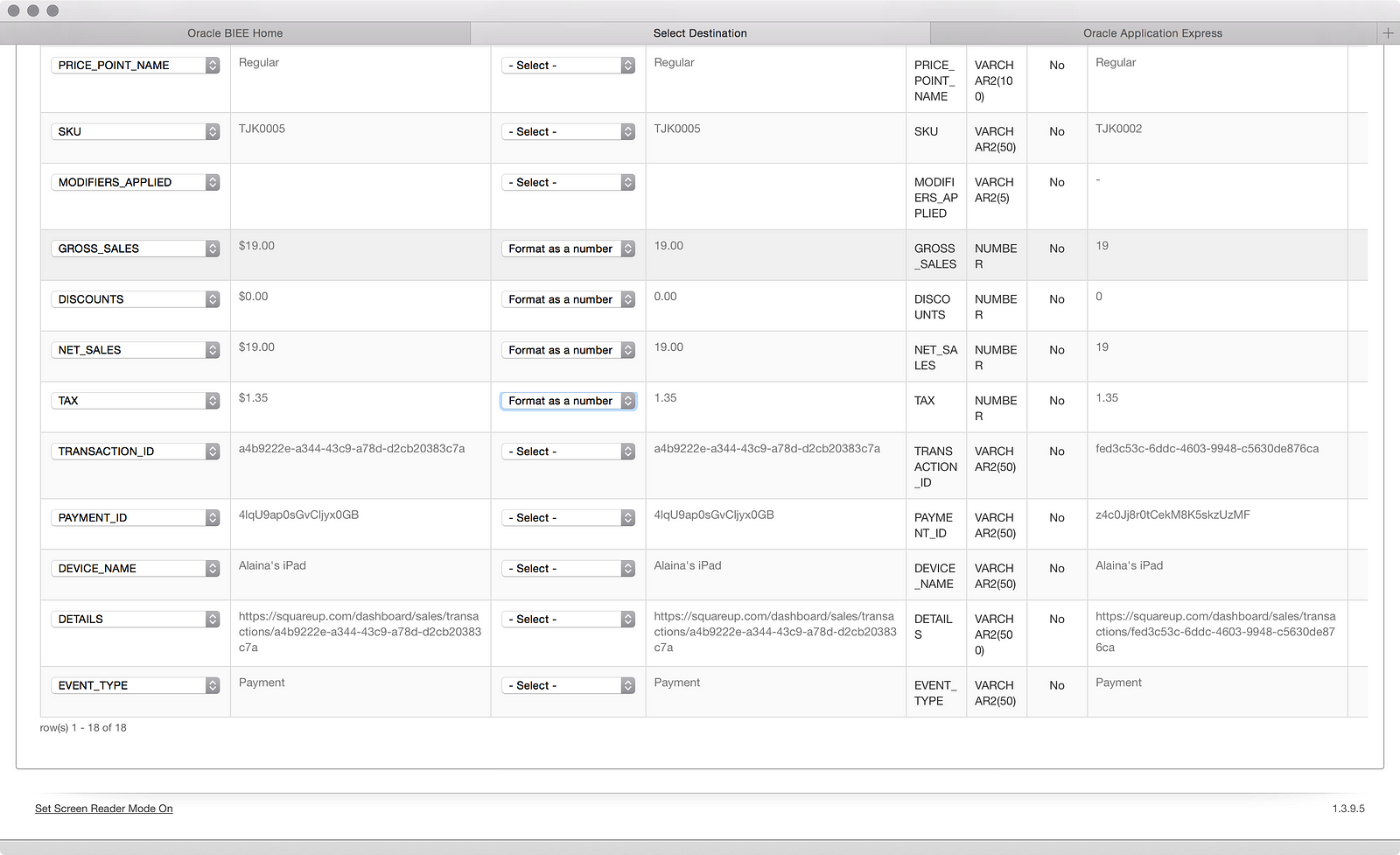
Now I’m ready to load and I click the Next button:
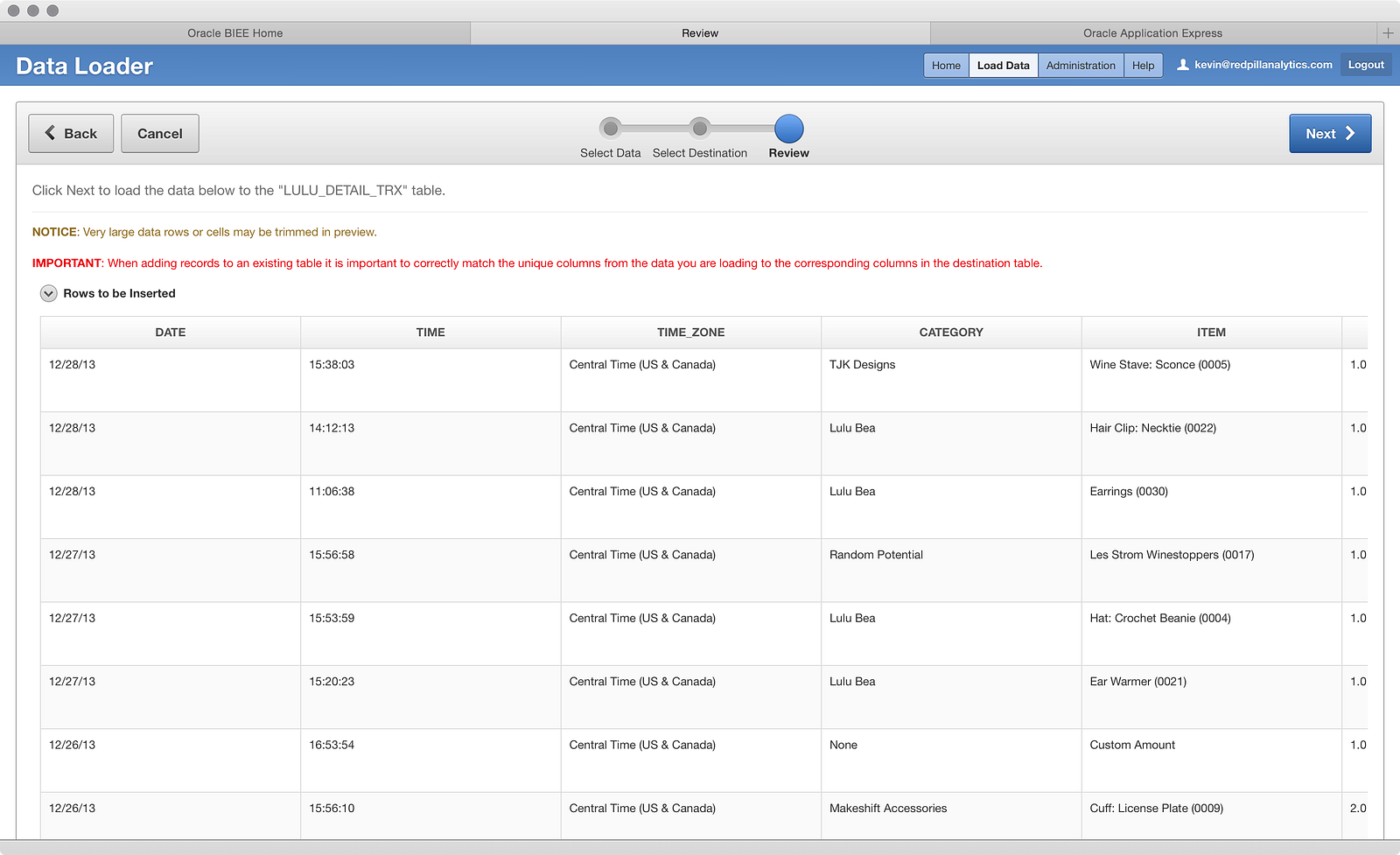
The data looks good, so I click Next to load:
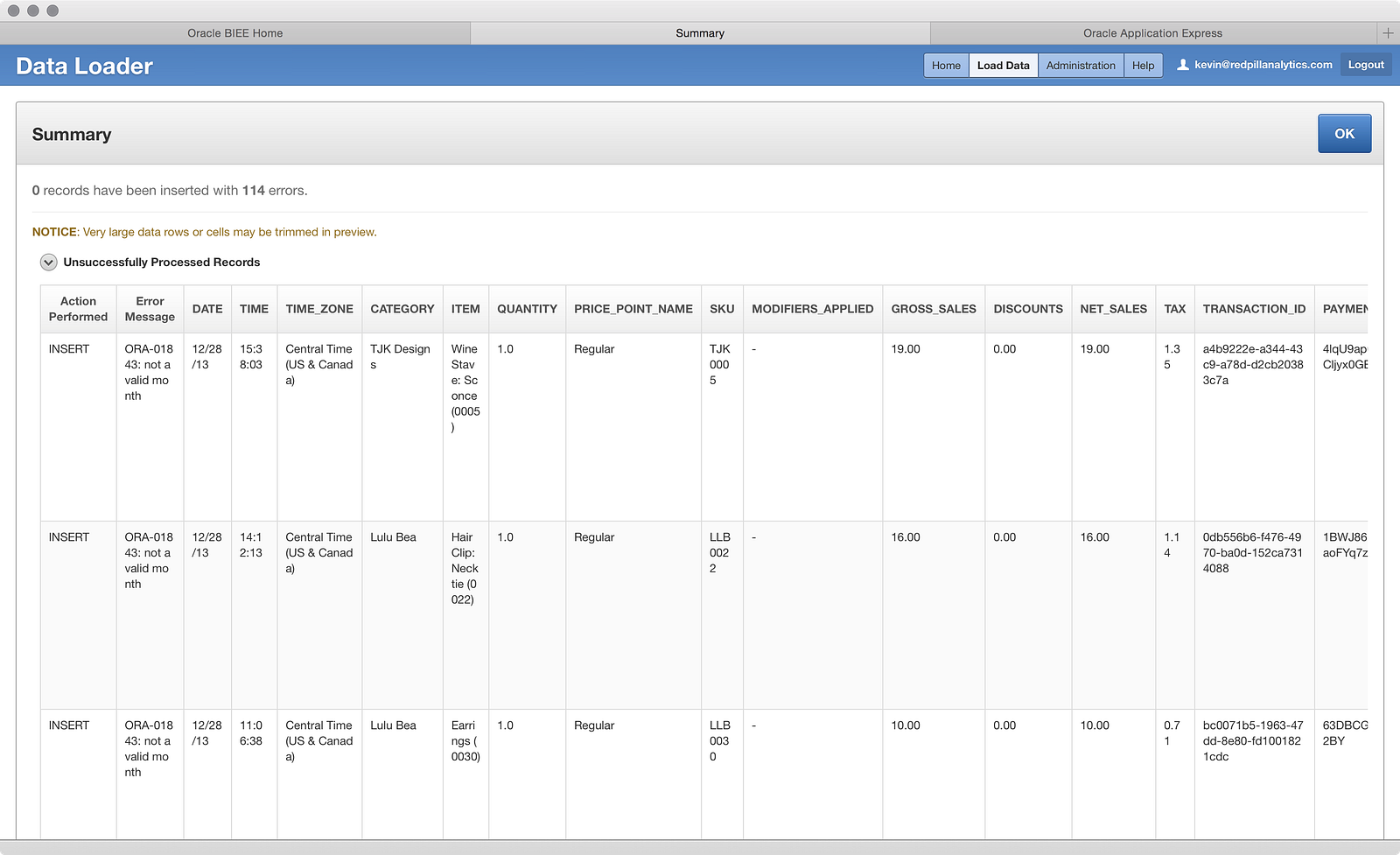
Hmm…the whole file bombed, which is not what I expected. The error message says not a valid month — that’s interesting. Let’s take a further look by clicking OK:
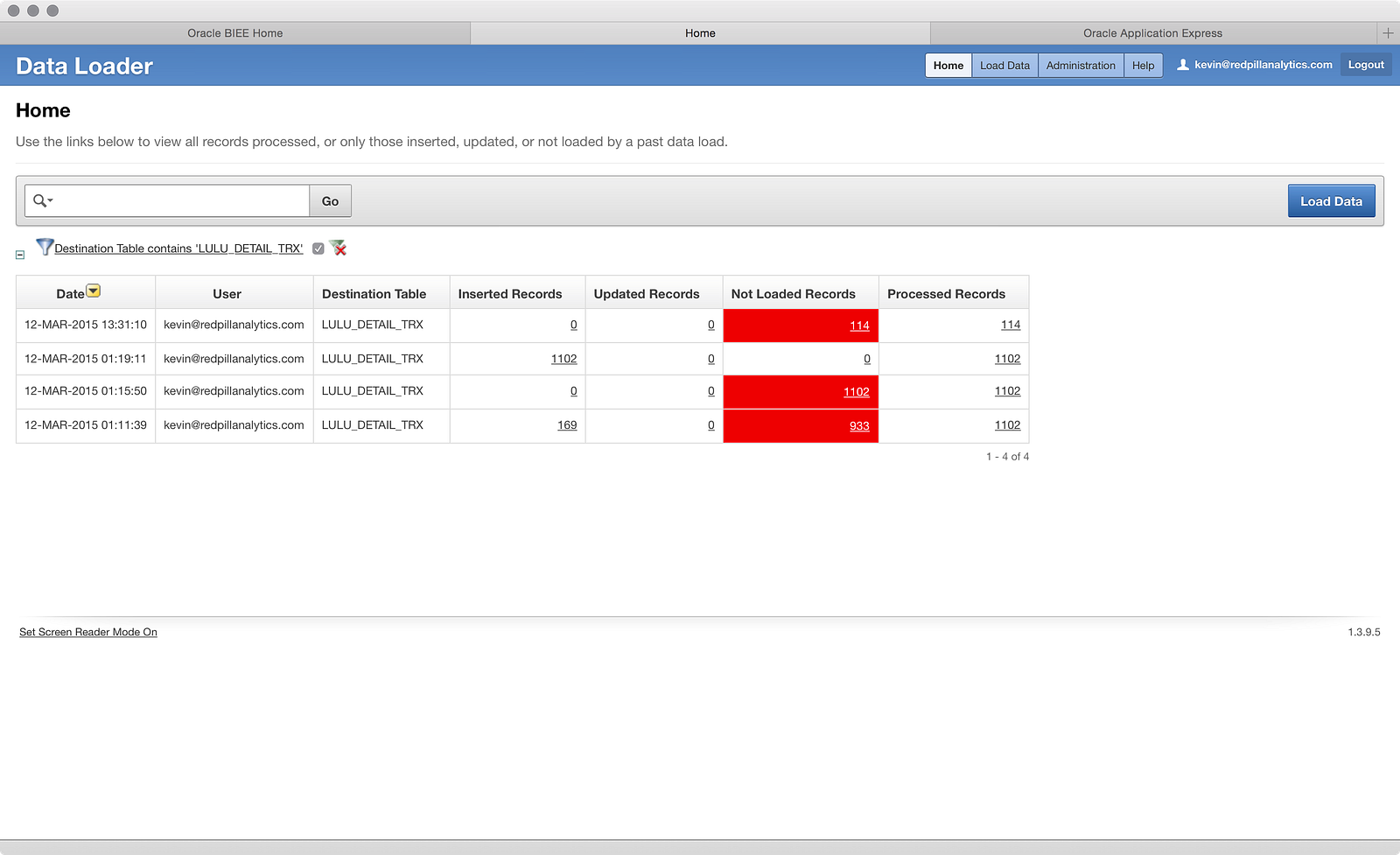
…and clicking on the 114 Not Loaded Records value above to get the error screen:
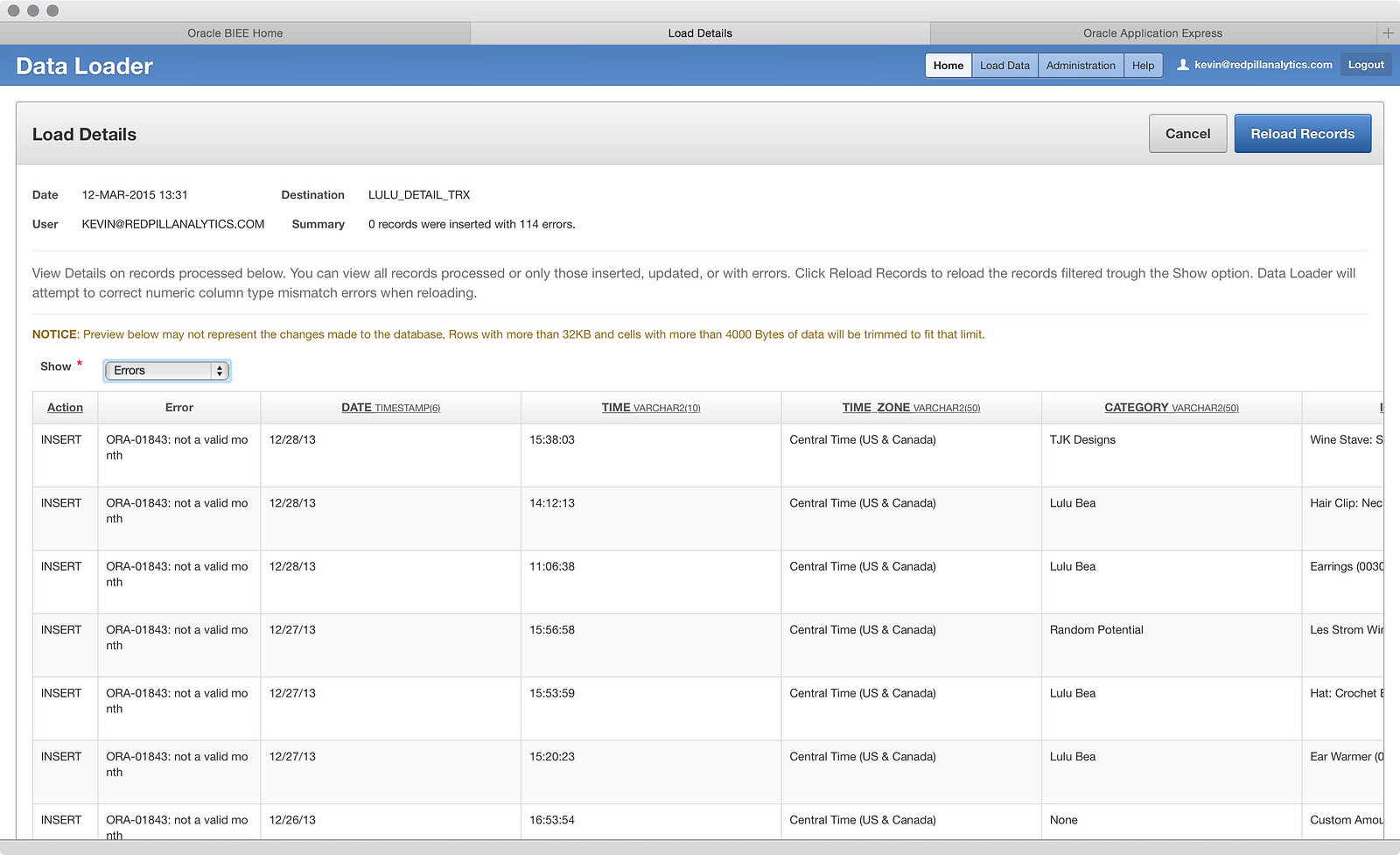
All this tells me so far is that ‘TIME’ is not the culprit this time like it was in Part 01 because it is loading into a VARCHAR field, not a TIMESTAMP. Does it have a problem with the ‘DATE’ column? What if I click on it?

Well isn’t that interesting? Clearly some funky things going on in the file, and I can also tell that the ‘NOTES’ field, which wasn’t supposed to be loaded, is still causing a problem. While I was hoping to leave it in there and just ignore it, I likely need to remove it:
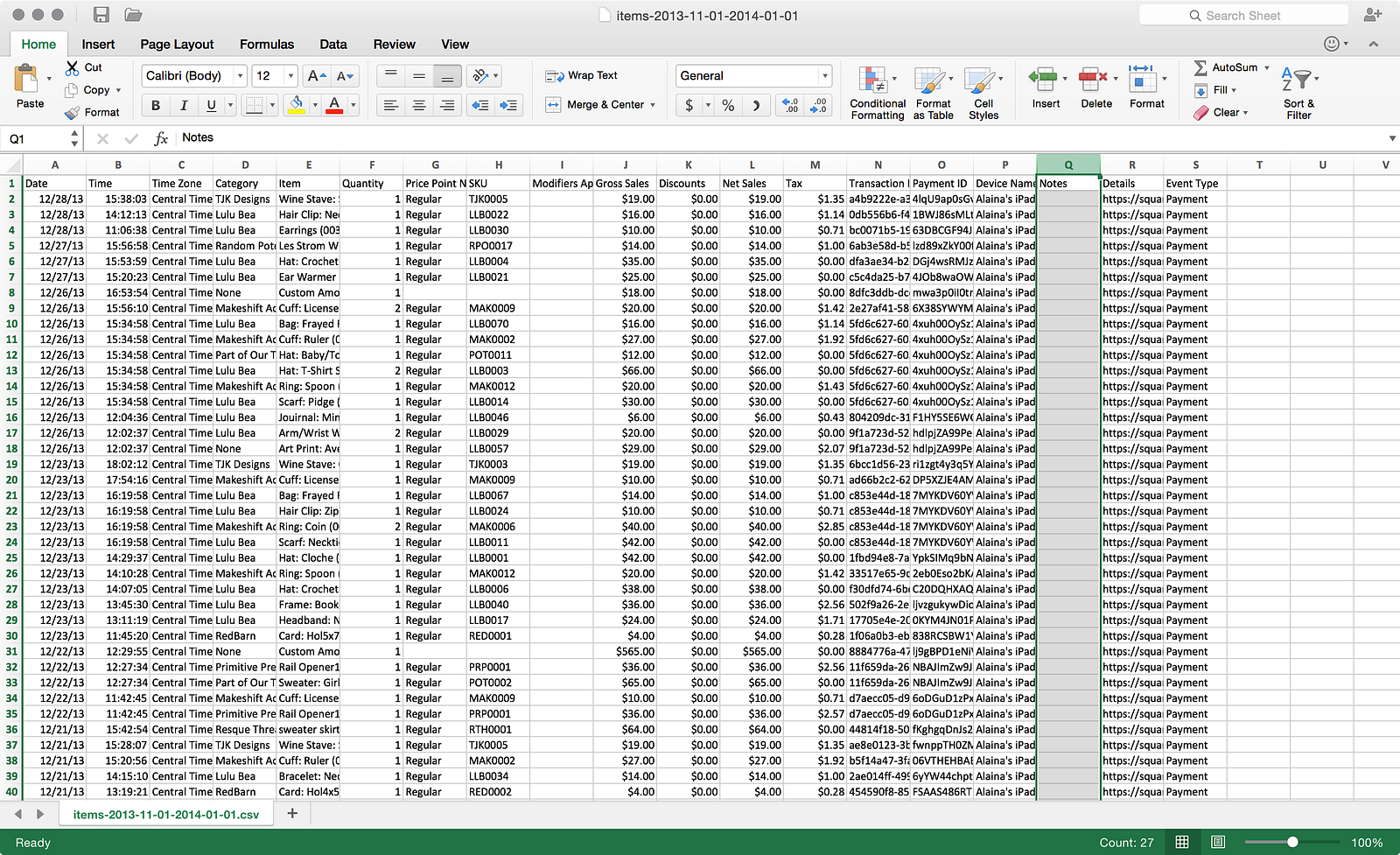
I also took a quick look at the file to make sure nothing was awry and it looks clean. After saving the file, I went back through the wizard steps again and got to the final step before loading:
Everything looks good, so let’s go ahead and load:

Ouch. 177 errors this time. Well, what that tells me is that there were problems before with the ‘NOTES’ column because there are 177 rows in the file. I double-checked that. However, all of the errors this time are clearly a TIMESTAMP issue. Let’s look at the file again:

I wonder…the first time I loaded the file, Oracle may not have cared about the date format being loaded into a TIMESTAMP column. Perhaps it was smart enough on an initial load to deal with a mm/dd/yy format. However, I know better in a regular Oracle db environment. Loading dates in that format can be troublesome, so what if I give it a different format mask in Excel?
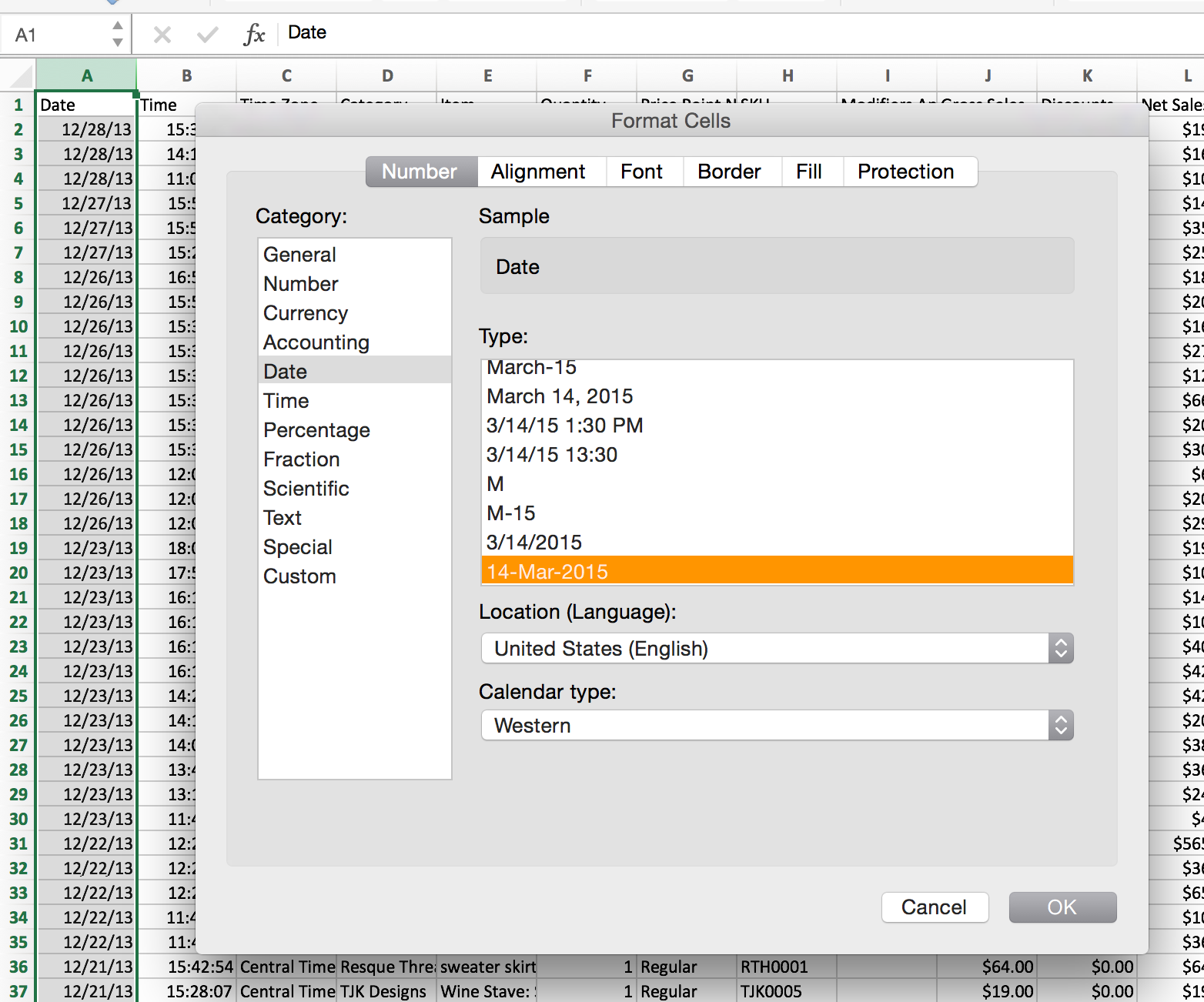
The Oracle db likes the ‘DD-MMM-YYYY’ format, so perhaps I can apply that mask in Excel to better enable the file to ingest properly without error. Now I have this as my source file:
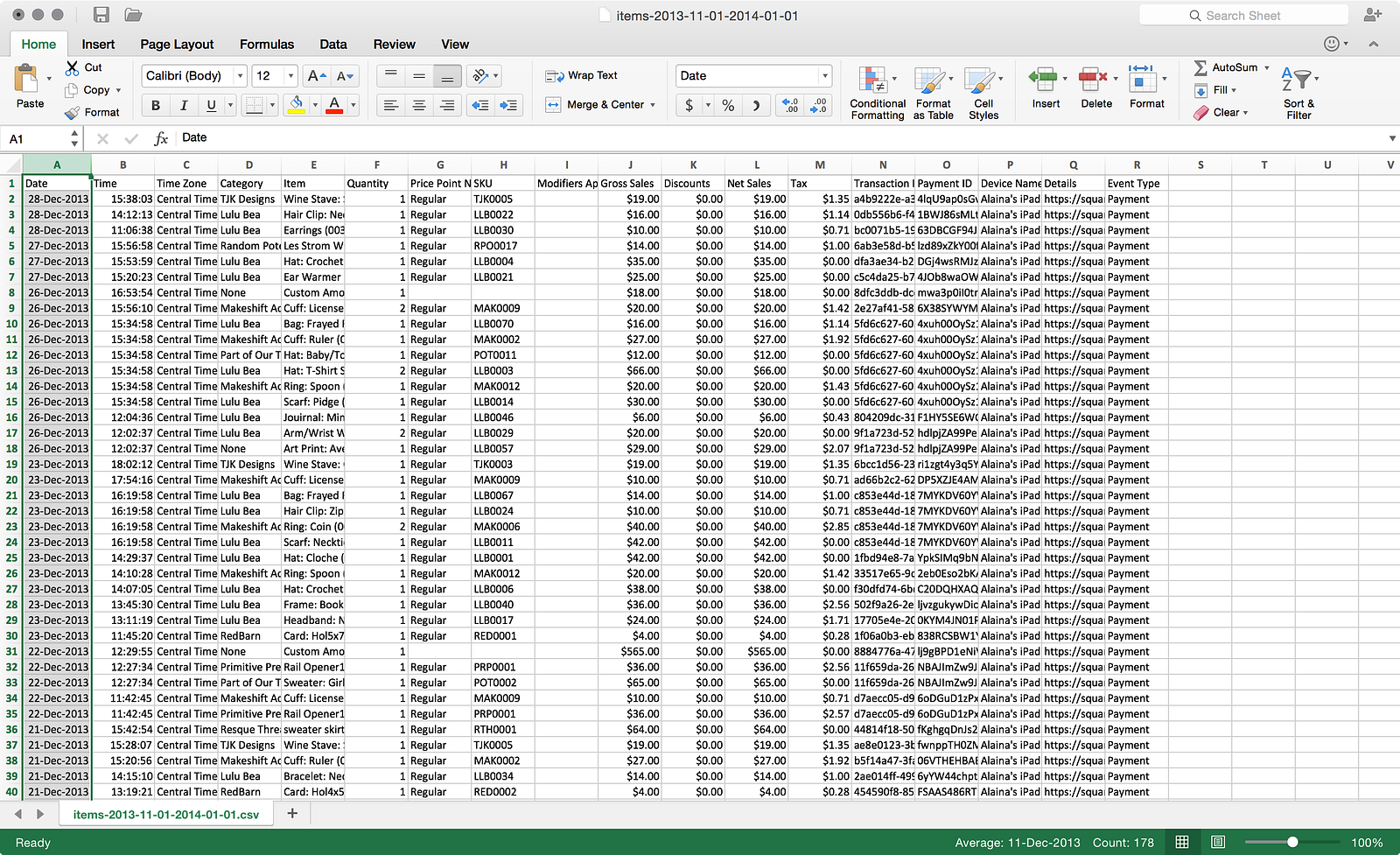
After going back through the wizard again, this time I get a successful load:
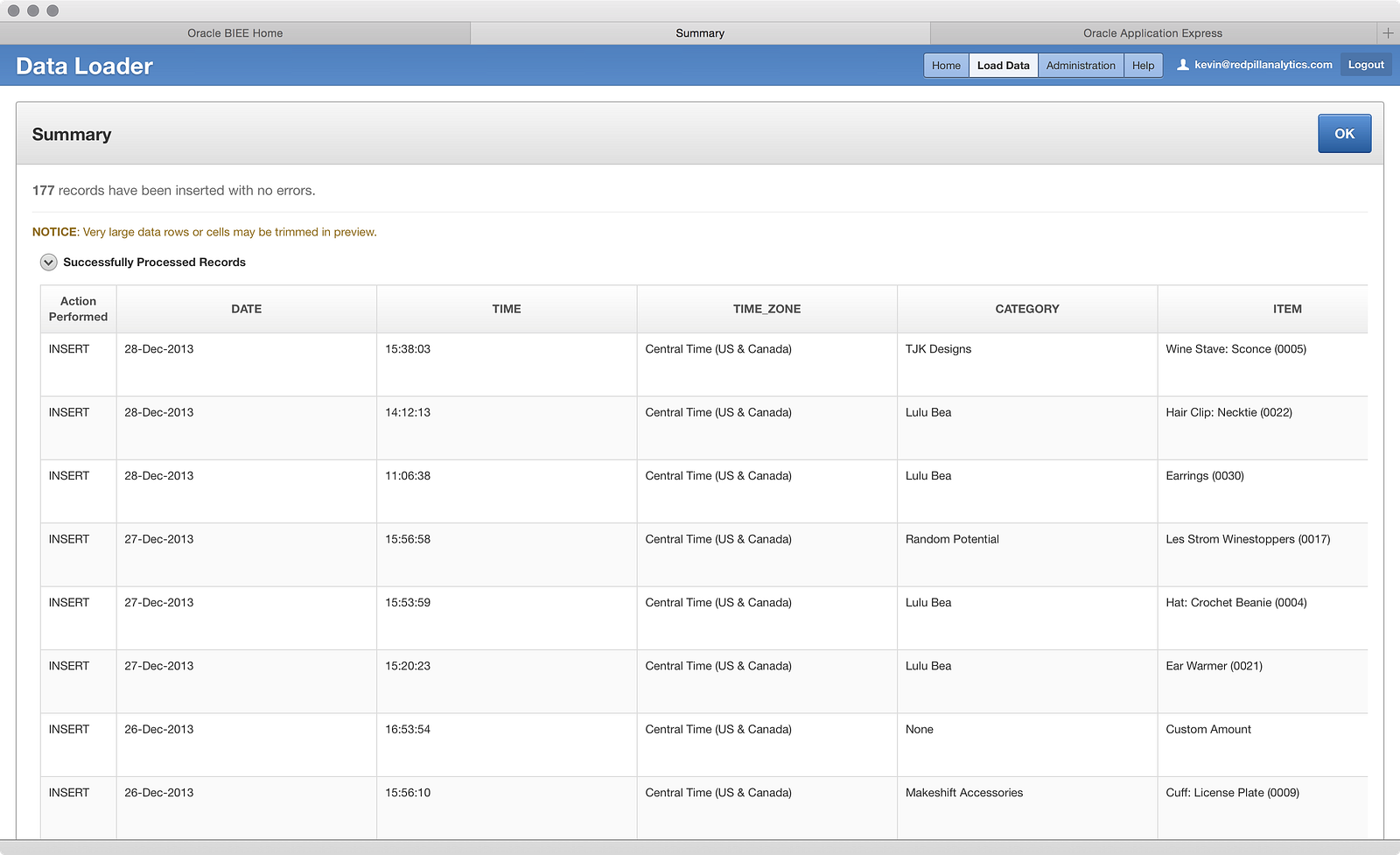
Interesting: the data loaded just fine. So clearly there is some work to do here on Oracle’s part to make loading DATE or TIMESTAMP data easier. It’s understandable that every date format under the sun can’t be supported, but MM/DD/YY is pretty standard and shouldn’t cause a problem. Now that I know what edits to make to the other file, I went ahead and did that and loaded the third file into the table:
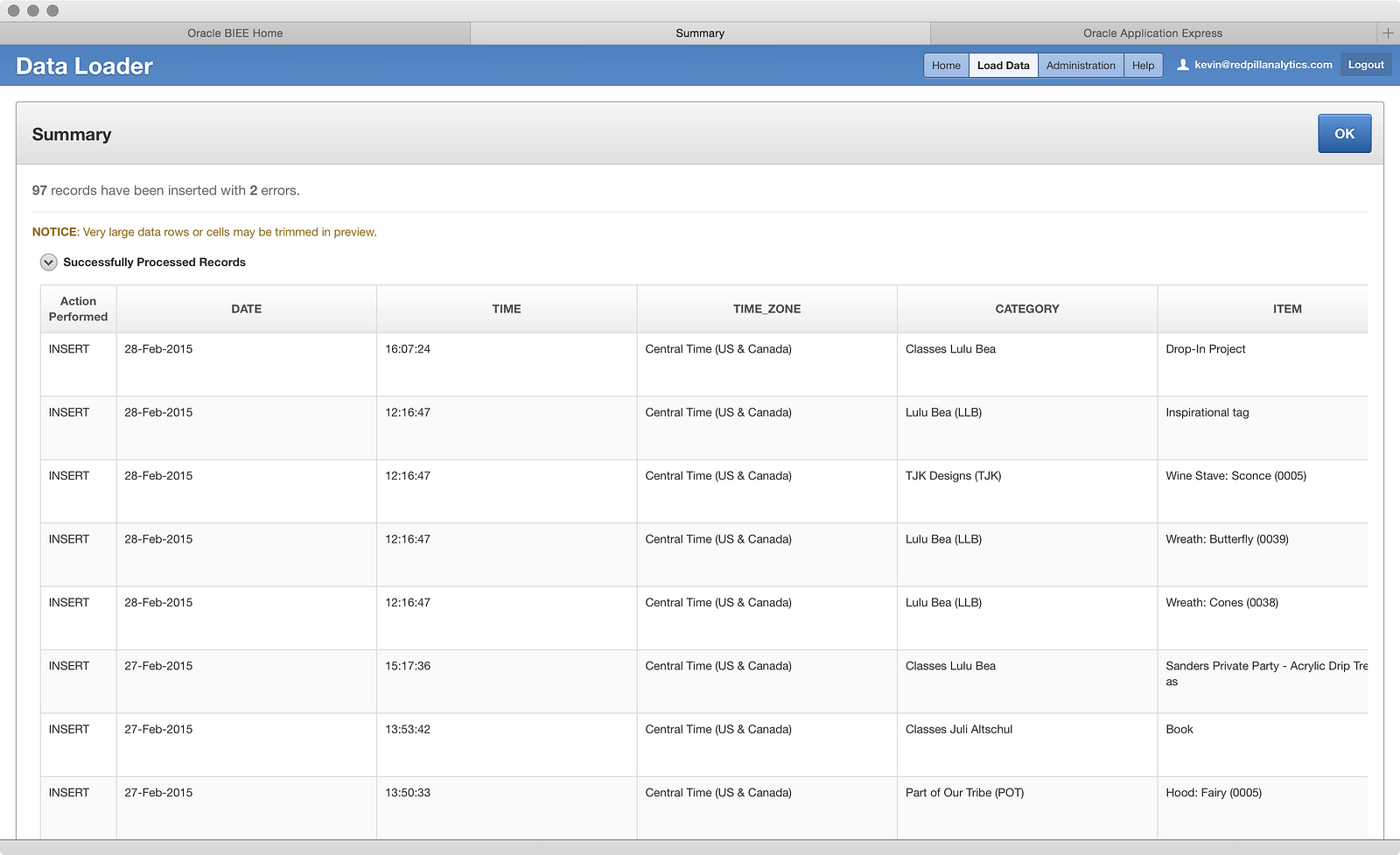
Two errors? Hmm, that’s interesting. Looking at the error screen, I can quickly tell the problem:
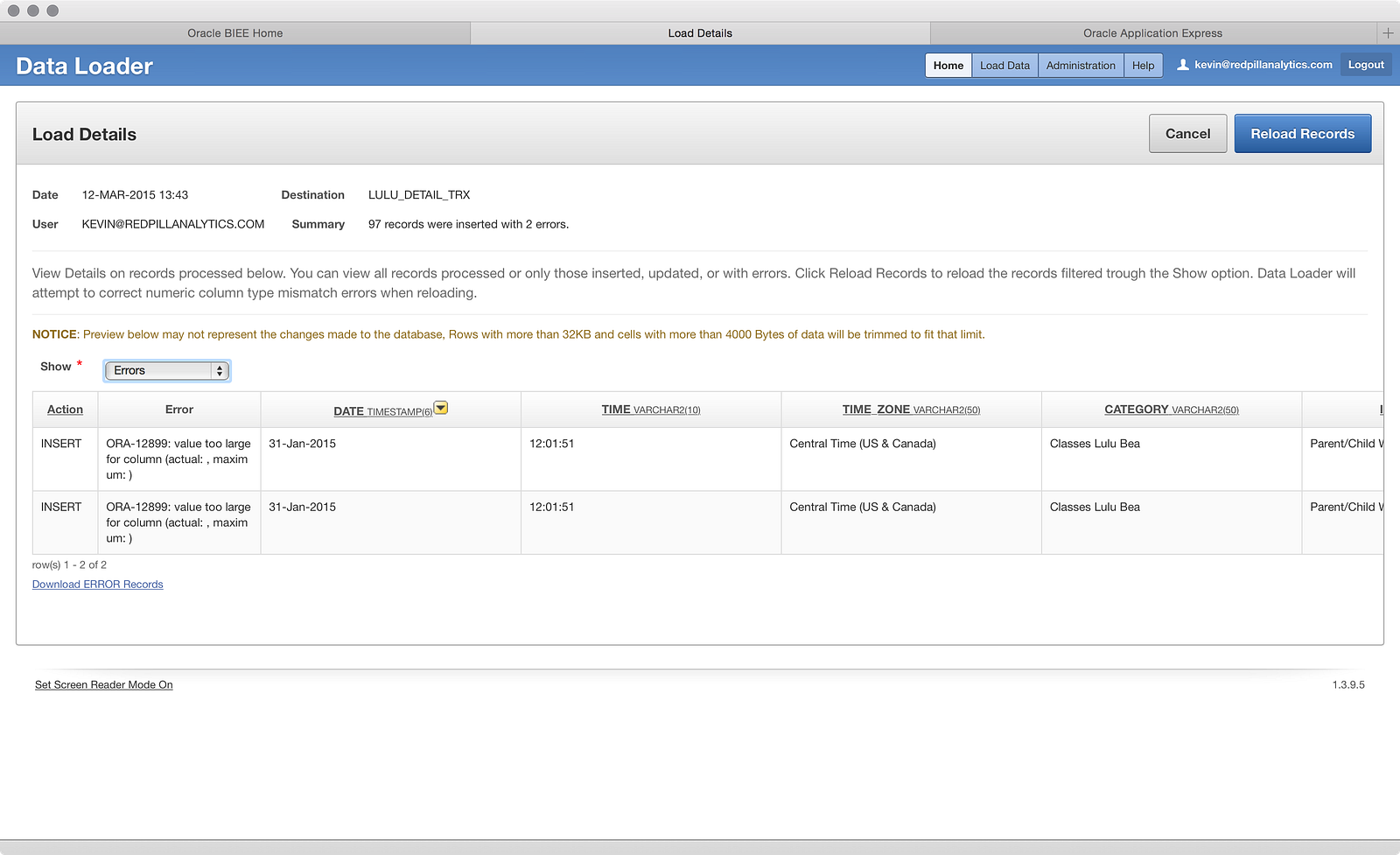
I was afraid of this happening. I swear I wasn’t purposefully foreshadowing before! Two rows have a column with text values larger than the defined column size. A quick scan through:
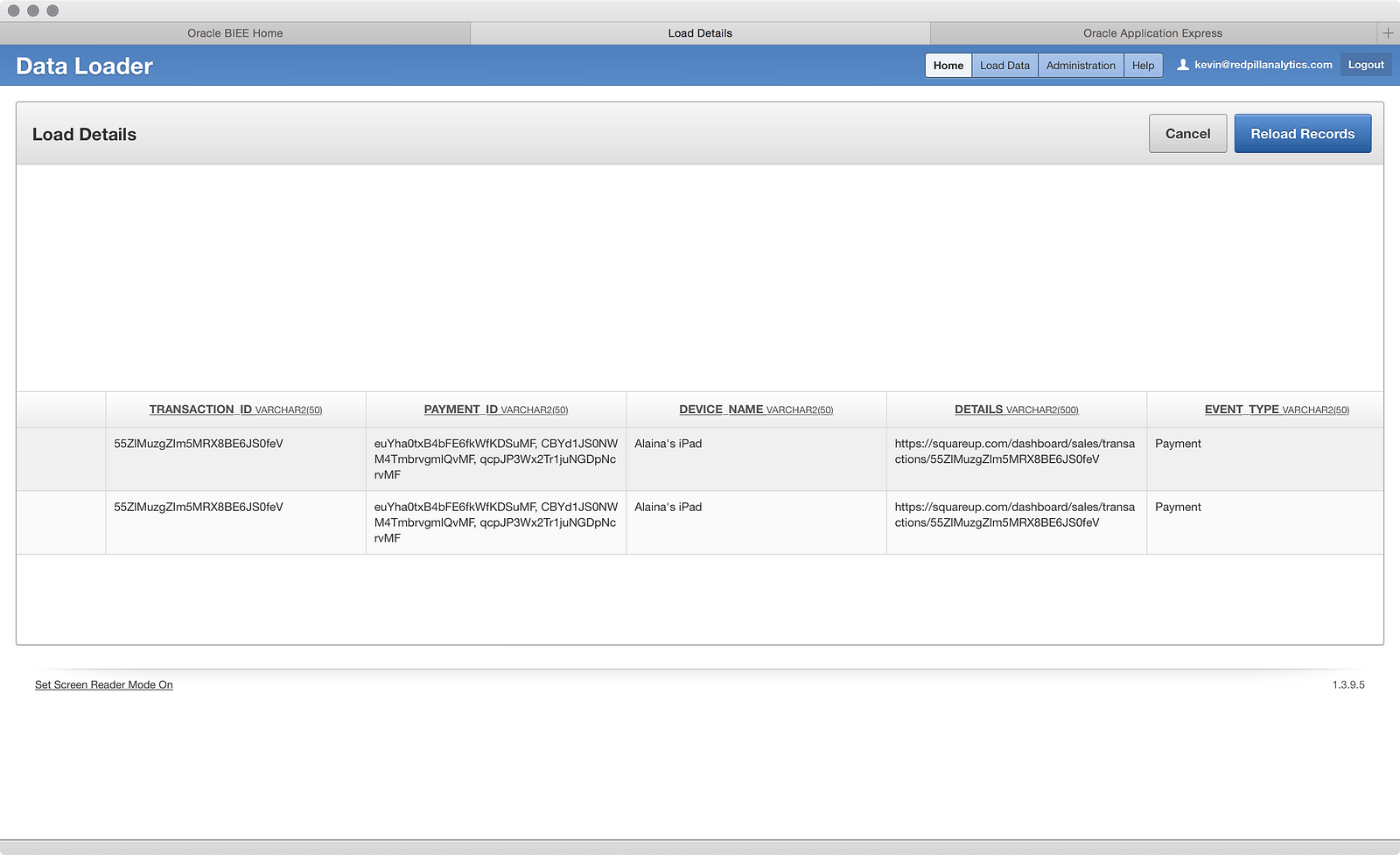
…shows it to be the ‘PAYMENT ID’ field. I’m not sure why, but it looks like the field contains multiple IDs in a single row. Fortunately, I can click the Reload Records button:
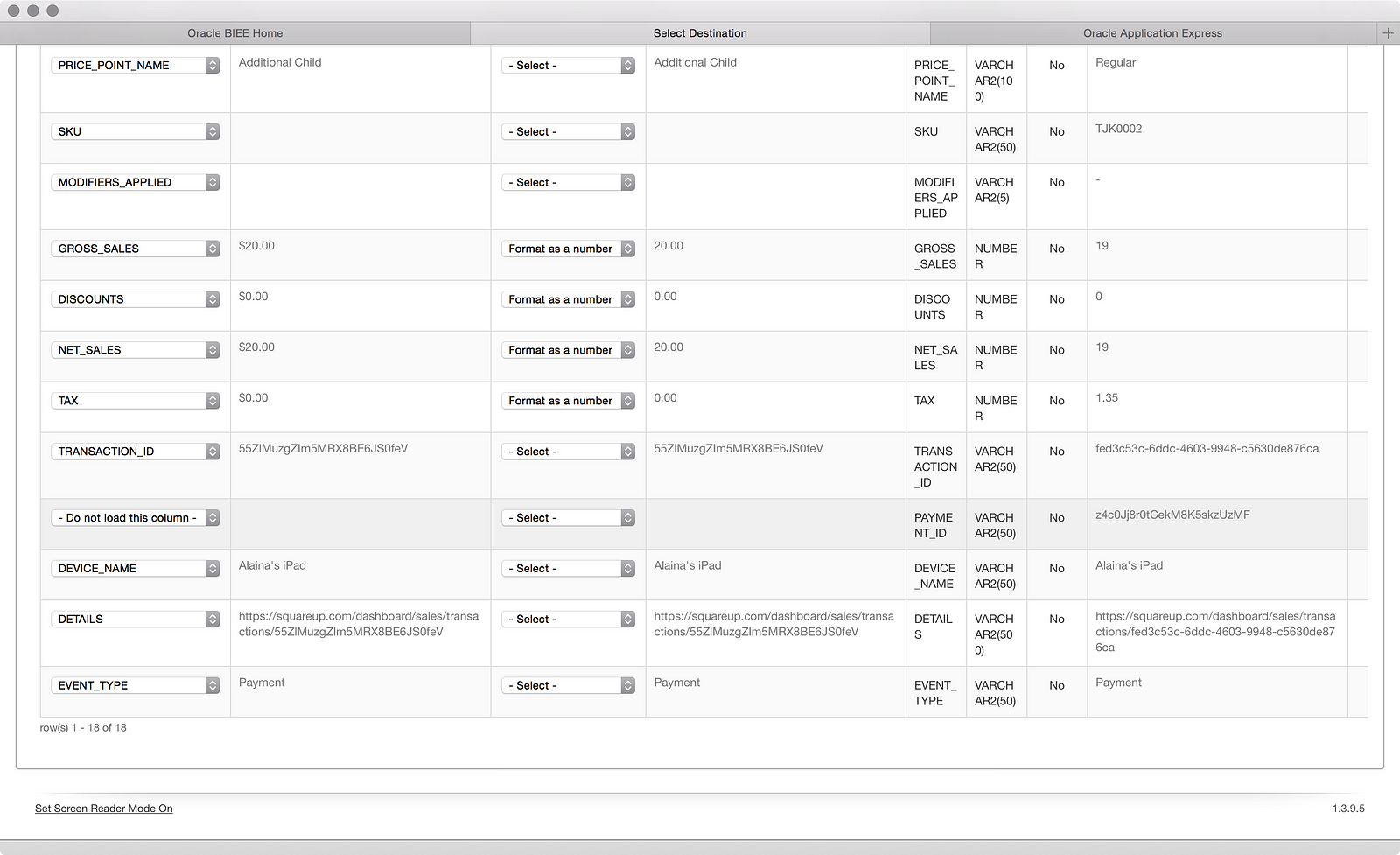
…mark the ‘PAYMENT ID’ column as “- Do not load this column -’ using the dropdown (I don’t care about this field for now), and reload those 2 records:
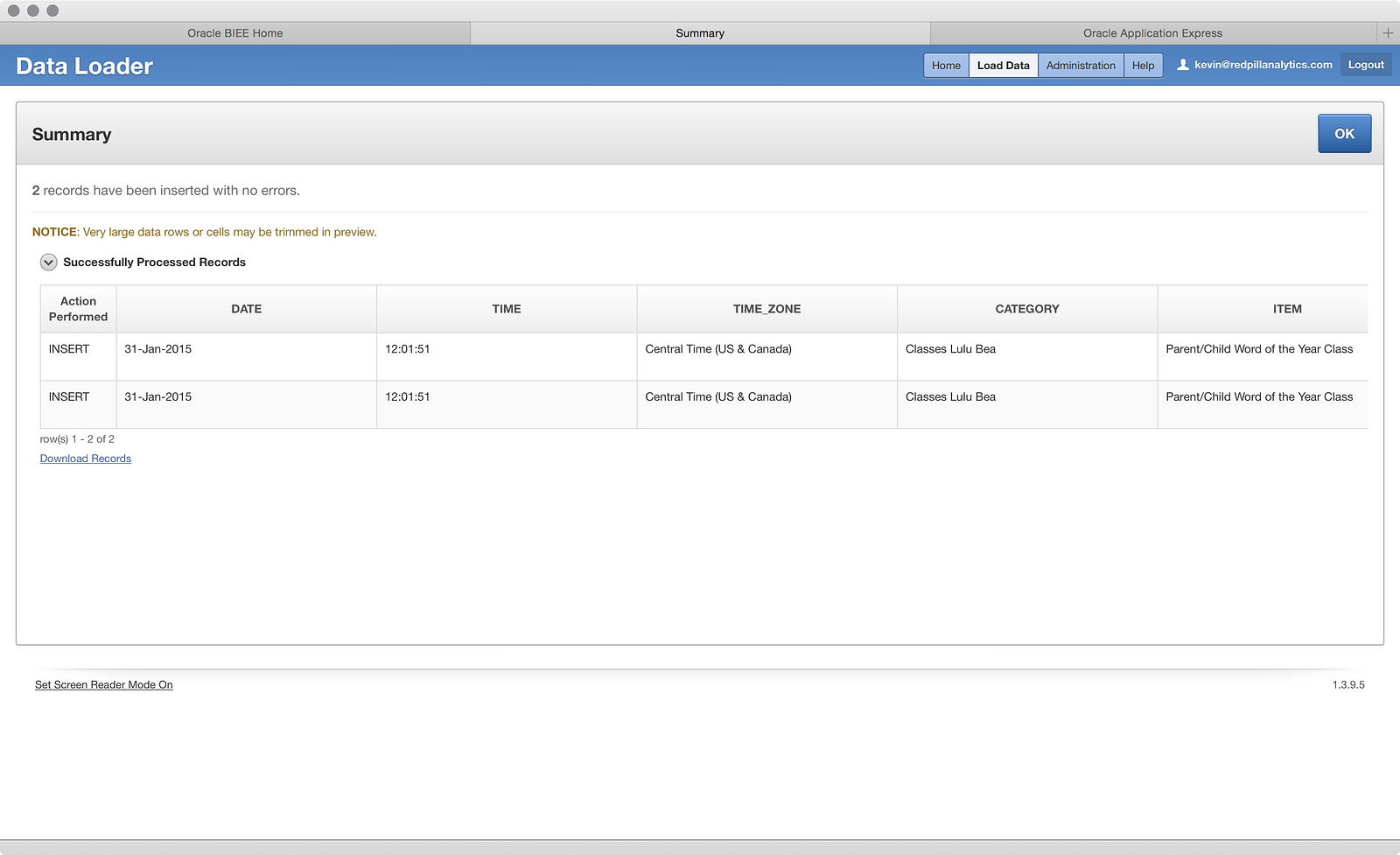
That’s a pretty handy thing to be able to do and is a step in the right direction toward dealing with data load issues, even if it’s not perfect (what if I had cared about those values?).
So to summarize, I exported three separate files from Square, used the first file to define the table structure upon load, then loaded two more files into the same table. The results is a sales transaction table with 1378 rows:
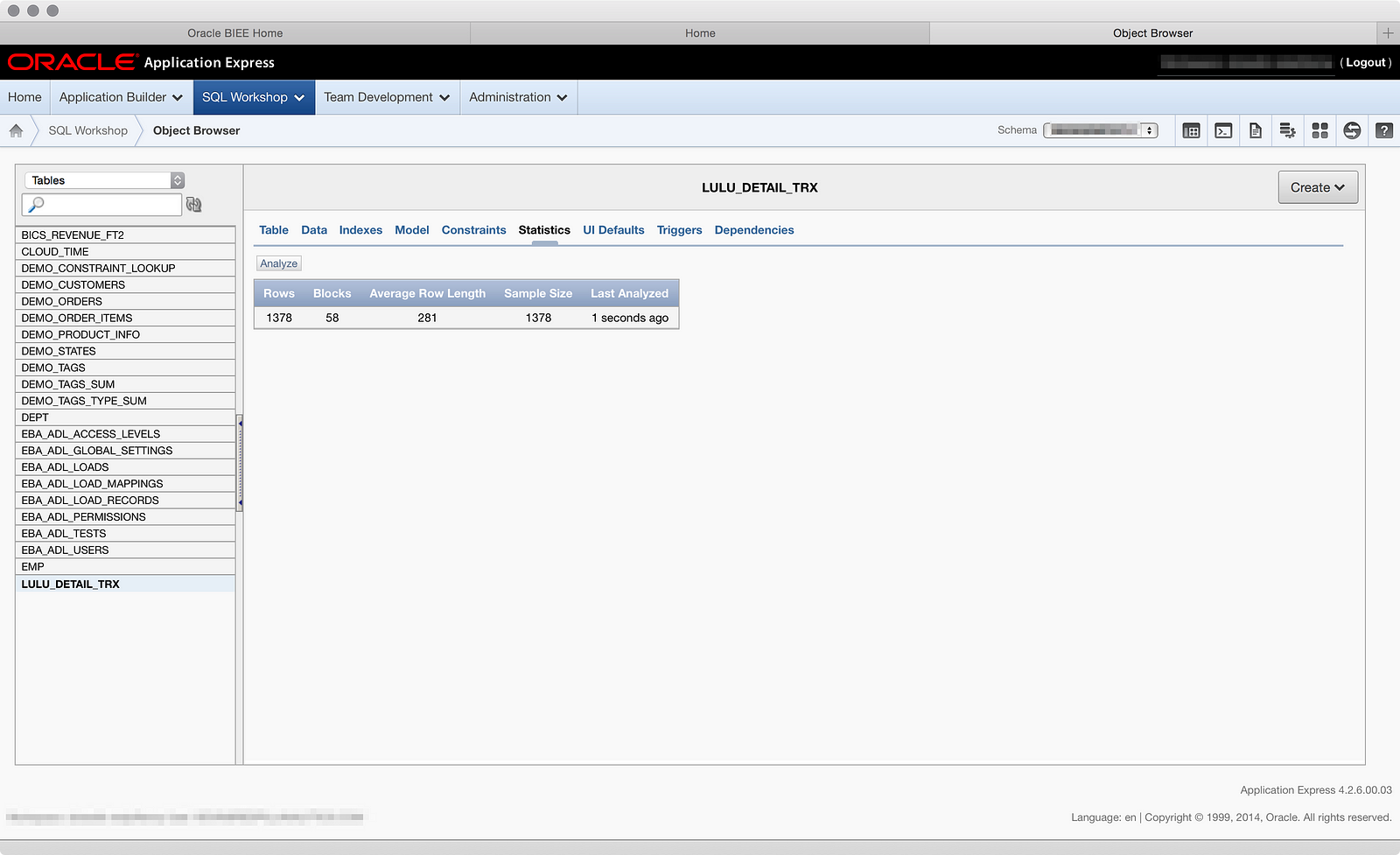
The interesting bit to note here is that for every new month of sales I want to load, I have two extra steps to accomplish after exporting the file: remove a column and apply a different date format mask to another. That could be a little annoying, or I might forget to execute these steps in the future. I can see how it might be valuable to pair BICS with some kind of data scrubbing tool that you can build rules into and execute without actually opening the file. But, I have data in a table, so now I can move onto metadata modeling, which I’m very eager to see, but you’ll have to wait for Part 03 for that. ☺