
Serverless computing is here to stay, and while the term “serverless” is a bit of a misnomer, the concept offers many benefits. Most notably, serverless computing allows developers to focus on writing code and not concern themselves with provisioning, configuring, or maintaining servers. One such example of serverless computing is AWS Lambda. Although there are several other serverless offerings across the public cloud landscape, I’ll focus on Lambda from here forward.
Understanding that Lambda functions can be written in Node.js, Python, Java, C#, and Go, it is clear that Lambda can be used in countless ways. In my world, one particular function that AWS Lambda lends a hand to is data integration. While it’s quite possible to use Lambda to build entire data integration frameworks, this blog will focus on something much less complex: Using AWS Lambda to connect to Snowflake Data Warehouse and run a simple SQL statement.
The prerequisites to be able to meet the objective are to have an AWS account with permissions to create Lambda functions as well as a Snowflake Data Warehouse account (AWS or Azure). For the encryption piece, an AWS Customer Master Key (CMK) is also required. A new key can be created using the AWS Key Management Service.
Ready… Set… Develop!
The first thing to do is to install the Snowflake Python connector and start writing some code. I typically prefer to test all of my code locally to ensure it runs without issue before introducing Lambda into the mix. A good place for information about Snowflake’s Python connector can be found on the Snowflake website. In fact, the script below is an enhanced version of verifying the Python installation.
To connect to Snowflake using Python, a few bits of information (at a minimum) are required to be able to connect: account, user id, and password. Optional parameters such as warehouse, database, role, and so on are not required but will likely be useful in other cases. I recommend becoming familiar with the additional Snowflake connection parameters that can be used in a Python program. The snippet of Python for a basic connection looks like this with hardcoded values:
import snowflake.connector con = snowflake.connector.connect( account = 'acme', user = 'mike', password = 'mysupersecretpassword' )
Don’t Hardcode! Use Variables
The connection above will work but what if I want to share my code with other developers? I certainly don’t want them to have my personal credentials. I also don’t want folks to have to modify the actual code if I can help it. Using variables as opposed to hard-coding values promotes reliable reuse of your program while also allowing sensitive information like passwords to be omitted from the core codebase. AWS Lambda facilitates this concept by letting developers use environment variables that are resolved at runtime. As an added bonus, Lambda also integrates with the Amazon Key Management Service (KMS) to allow values to be encrypted without much effort.
By using environment variables, I can abstract the values, share the script, and allow others to input information without modifying the code. Refactoring the code to use environment variables, the Python script starts to take a better shape.
import snowflake.connector import os #set all of the environment variables #variables need to be set in the aws lambda config env_snow_account = os.environ['snowflake_account'] env_snow_user = os.environ['snowflake_user'] env_snow_pw = os.environ['snowflake_pw'] #connect to snowflake data warehouse using env vars con = snowflake.connector.connect( account = env_snow_account, user = env_snow_user, password = env_snow_pw )
There’s still one problem: the password is stored in clear text. This is where the AWS Key Management Service can come in handy. Keep in mind that there are several methods that can be used to authenticate with Snowflake and leveraging AWS KMS is one of them.
import snowflake.connector
import os
import boto3
from base64 import b64decode
#set all of the environment variables including the encrypted password
#variables need to be set in the aws lambda config
env_snow_account = os.environ['snowflake_account']
env_snow_user = os.environ['snowflake_user']
env_snow_pw_encryp = os.environ['snowflake_pw']
env_snow_pw_decryp = boto3.client('kms').decrypt(CiphertextBlob=b64decode(env_snow_pw_encryp))['Plaintext']
#connect to snowflake data warehouse using env vars
con = snowflake.connector.connect(
account = env_snow_account,
user = env_snow_user,
password = env_snow_pw_decryp
)Now that the connection details are taken care of, the program needs a Lambda injection point and something to execute against the database. The code below will connect to Snowflake and return the current version. This is just a simple script to test connectivity; if a value is returned from the database, the connection was successful.
[/vc_column_text][/vc_column][/vc_row][vc_row][vc_column][vc_column_text]
#!/usr/bin/env python
import snowflake.connector
import os
import boto3
from base64 import b64decode
#set all of the environment variables including the encrypted password
#variables need to be set in the aws lambda config
env_snow_account = os.environ['snowflake_account']
env_snow_user = os.environ['snowflake_user']
env_snow_pw_encryp = os.environ['snowflake_pw']
env_snow_pw_decryp = boto3.client('kms').decrypt(CiphertextBlob=b64decode(env_snow_pw_encryp))['Plaintext']
#simple query to return a value from Snowflake
query = "SELECT current_version()"
#add lambda injection point
def lambda_handler(event,context):
#connect to snowflake data warehouse using env vars
con = snowflake.connector.connect(
account = env_snow_account,
user = env_snow_user,
password = env_snow_pw_decryp
)
#run the test query to check if snowflake returns a result
cur = con.cursor()
try:
cur.execute(query)
one_row = cur.fetchone()
print(one_row[0])
finally:
cur.close()
con.close()[/vc_column_text][/vc_column][/vc_row][vc_row][vc_column][vc_column_text]
Create a Lambda Function
A new AWS Lambda function can be created by uploading a .zip deployment package with the script above and its underlying dependencies. Check out the AWS documentation for assistance creating a deployment package. If you’re new to Lambda, I highly recommend reading Liz Rice’s awesome blog on using Docker to create AWS Lambda deployment packages, appropriately titled: How to claw your way out of AWS Lambda function hell using the power of Docker.
After the .zip has been uploaded to AWS Lambda, environment variables need to be created to match what’s in the Python script:
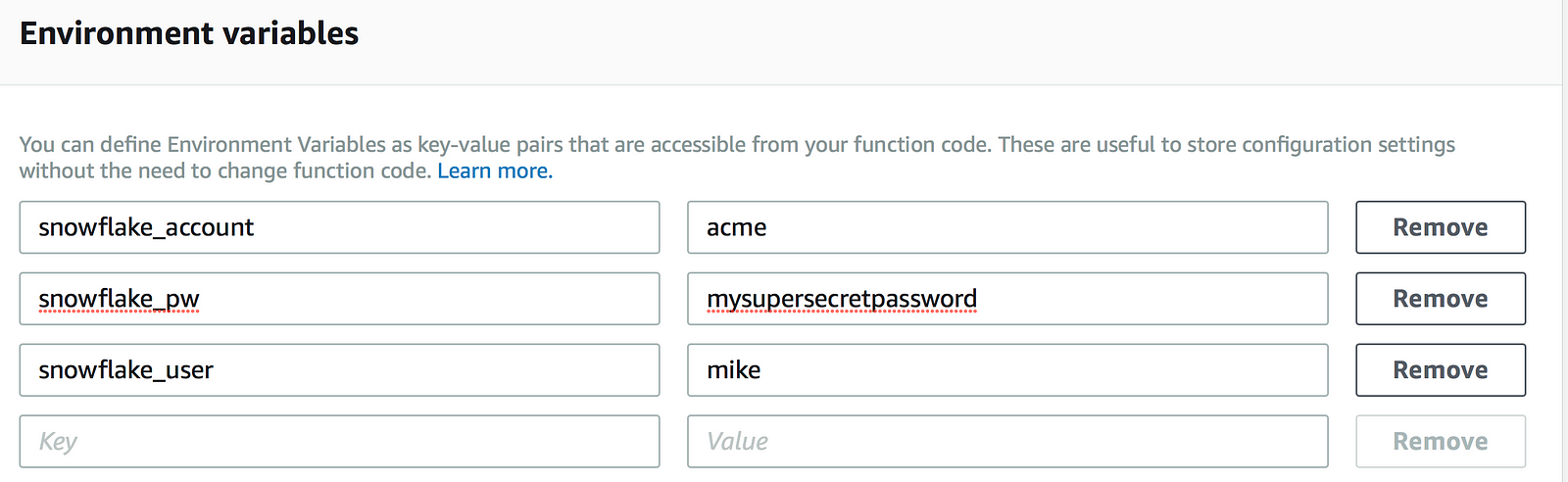
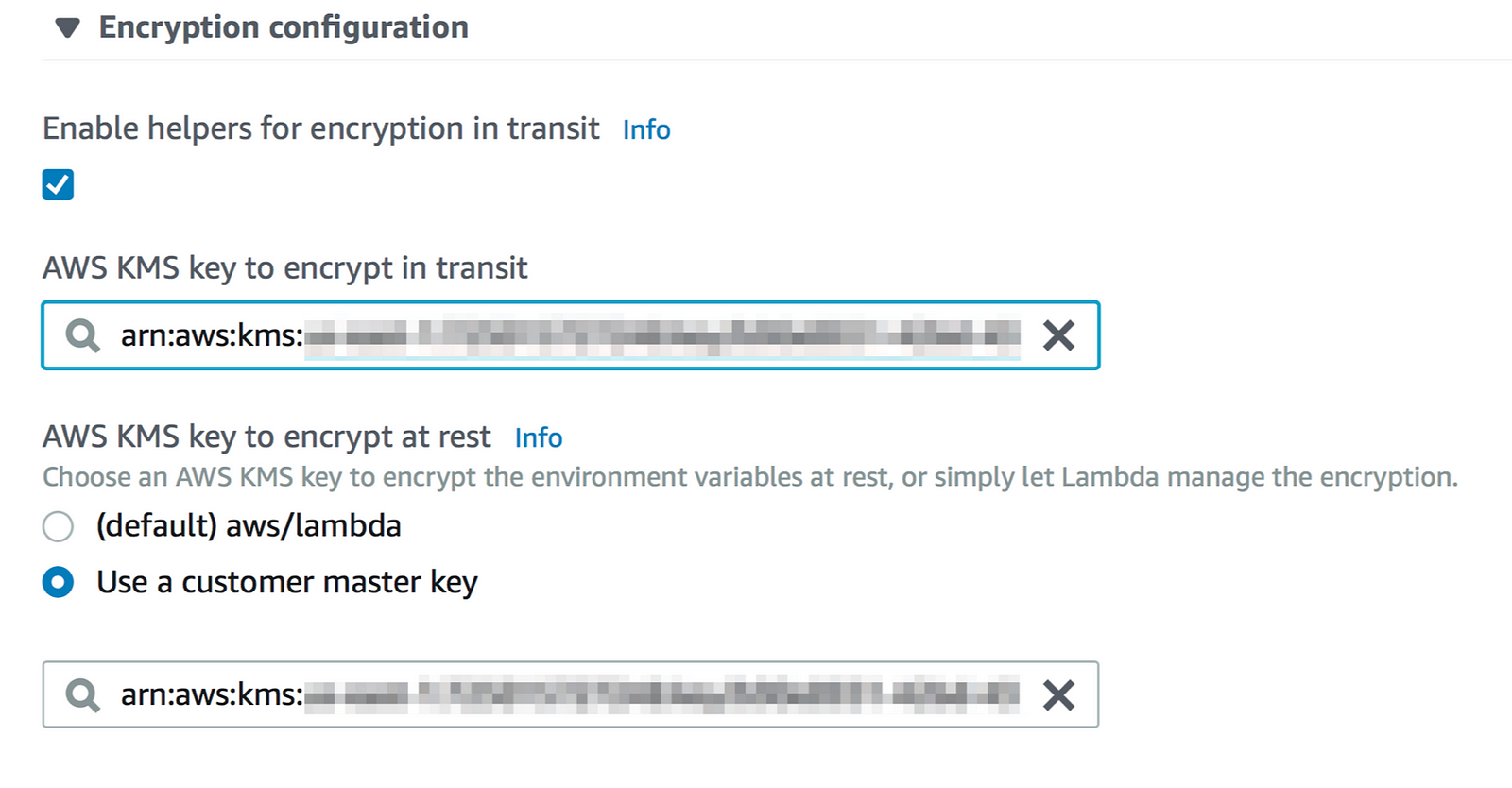
To encrypt the snowflake_pw value, expand the Encryption configuration and check the box for ‘Enable helpers for encryption in transit’. Select the desired KMS key from the dropdown menu(s). The screen below shows a custom KMS key selected for both encryption in transit and encryption at rest.
An Encrypt button is now displayed for each variable:

Clicking Encrypt for snowflake_pw masks the value:

And saving and refreshing the page now shows an encrypted string without the option to decrypt the value:
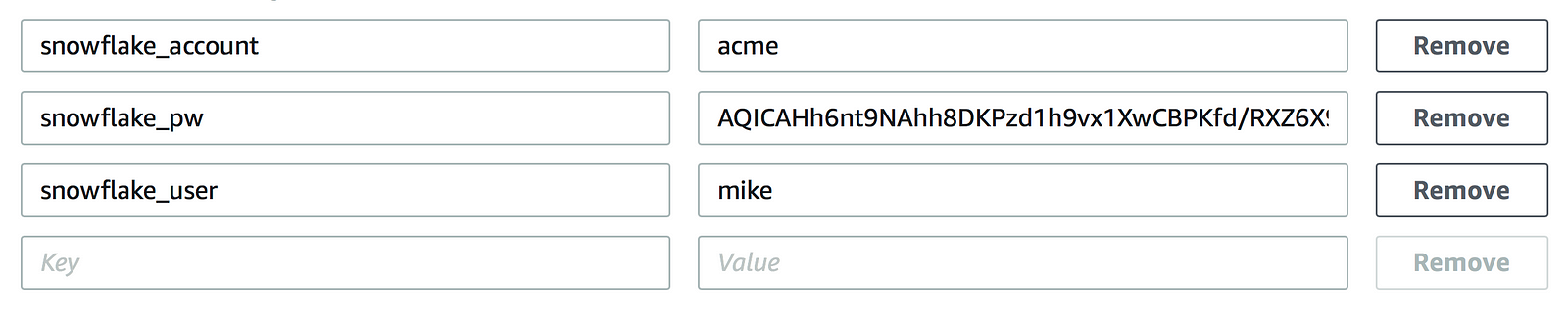
At this point, it’s time to test the function to check if the Python script is listening for the environment variables created for the Lambda function and that a successful connection to Snowflake is made.
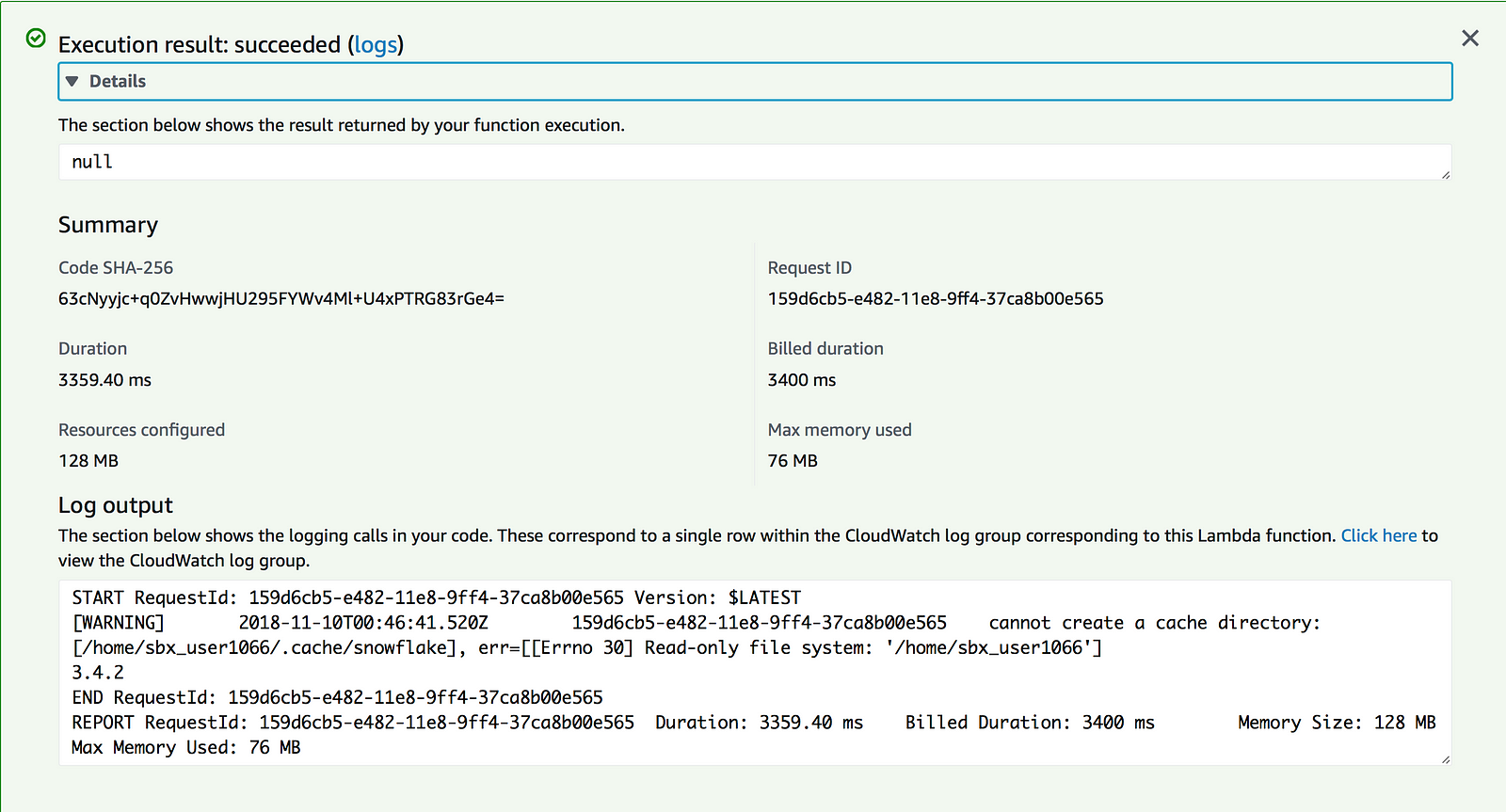
Excellent, the Lambda function succeeded and returns that 3.4.2 is the current Snowflake version. A review of the Snowflake web UI to double check that the query was run shows as expected:

Now that the template for connecting to Snowflake is working, the code can be reused and enhanced to write more complex logic to satisfy future use cases.
Note: The function works but if anyone can figure out how to get rid of that pesky warning about the cache directory, let me know and I’ll update this blog. I attempted to follow the suggestions here without success.
But… Lambda is not for Everything
It is important to mention a few things when considering Lambda and other serverless functions for data integration. Lambda and its counterparts — mainly Google Cloud Functions and Microsoft Azure Functions — are intended to facilitate microservice architecture and are not meant for building long-running, monolithic programs. To that end, AWS Lambda functions have a maximum timeout of 15 minutes. Similarly, Microsoft Azure Functions and Google Cloud Functions have maximum timeouts of 10 and 15 minutes, respectively. A second important point to make is that it is critical that functions are written to be idempotent. That is, running the function multiple times should not have a material effect on the outcome.
If you have worked in a traditional data integration setup you might be thinking “no way can I guarantee that each of my tasks finishes within 15 minutes and now you say the function might run more than once even though I didn’t tell it to?!” Correct; which are a few reasons why Lambda isn’t for everything. There are other tools that are much more adept at creating classic ELT/ETL tasks and execution plans. Suffice to say that you should do your homework before committing to a particular approach.
Need help?
Red Pill Analytics is a Snowflake Solutions Partner experienced not only in working with Snowflake as well as AWS but also advising organizations on overall data strategy. Our knowledge spans a variety of offerings across all of the major public cloud providers. From proof-of-concept to implementation to training your users, we can help. If you are interested in guidance while working with Snowflake, AWS, or any of your data projects, feel free to reach out to us any time on our website or find us on Twitter, Facebook, and LinkedIn.
[/vc_column_text][/vc_column][/vc_row]