
In my previous post, I discussed the transition from a Type 1 to a Type 2 Dimension structure after initial implementation. Today we’ll maintain our focus on Type 2 Dimensions and highlight derived effective dating and its timestamping implications.
Why Effective Date?
Within Type 2 Dimensions, it is essential that each record be effective dated with an effective start date and an effective end date. These dates ensure your transactions are properly linked to the dimension record in effect at the time your transaction occurred. For example:


Effective dates should be as precise as possible—down to the second, if available.
Sourcing vs. Deriving Effective Dates
 Ideally, effective dates should be pulled directly from your source system of record along with their updated attributes. A direct pull of these dates from your sources will ensure that the data within your warehouse mirrors what is in effect within your transaction systems.
Ideally, effective dates should be pulled directly from your source system of record along with their updated attributes. A direct pull of these dates from your sources will ensure that the data within your warehouse mirrors what is in effect within your transaction systems.
In many cases, however, effective dates are not available within the source and must be derived via your ETL processes. Through change detection, your ETL processes should determine the need for a new dimension record and effective date the new record with the date and time at which it was inserted. In an Oracle Database environment, the SYSDATE function would be used for this date and time purpose.
Timestamping Implications
While precise effective dating — down to the second, if available — is essential for accuracy, derived effective dating introduces some exceptions to the precision rule. When utilizing the SYSDATE function for effective dating, the date and time, down to the second, at which the record was inserted will be the effective date stored on the dimension record. This derived mechanism inadvertently ties your effective dates directly to the time of day that your ETL processes run. In a world of batch, rather than real time, loads, this can lead to unexpected results. Let’s walk through the following example:
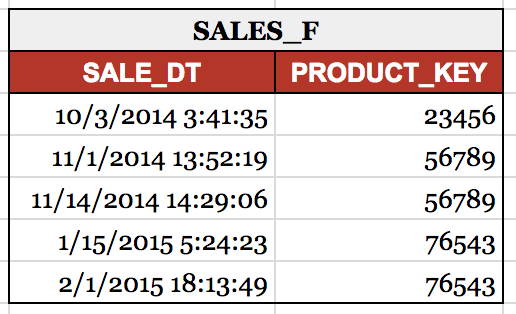
At 12:15 PM on 1/15/2015, we kick off our daily ETL process to load our Products Dimension (PRODUCTS_D) and our Sales Fact (SALES_F). Upon completion, we observe the following results:


We see that the sale that occurred at 5:24:23 AM on 1/15/2015 is tied to the Product record in effect from 10/15/2014 11:46:05 AM — 1/15/2015 12:15:17, or PRODUCT_KEY 56789. However, as we are deriving effective dates rather than pulling them from the source and we are only loading once daily, we cannot with accuracy assert that PRODUCT_KEY 56789 is actually in effect until 12:15:17 on 1/15/2015. This time, 12:15:17, is merely reflective of our ETL run time, and not an actual record change time. Rather, due to the daily loads, our only accurate conclusion can be that the record had changed from the day before.
Our results should instead reflect the following:

Luckily, we can easily resolve this issue simply by truncating SYSDATE to reflect the interval at which your ETL process is run. For example, if you run your ETL daily, you would truncate SYSDATE so that your effective dates reflect midnight, or the start, of that day. If your ETL is run hourly, you would truncate SYSDATE to the beginning of the hour. I have provided a starter list of truncate functions for this purpose below.
- Annual Load: TRUNC(SYSDATE, ‘Y’)
- Quarterly Load: TRUNC(SYSDATE, ‘Q’)
- Monthly Load: TRUNC(SYDATE, ‘MM’)
- Weekly Load (Sunday Start of Week): TRUNC(SYSDATE, ‘D’)
- Daily Load: TRUNC(SYSDATE)
- Hourly Load: TRUNC(SYSDATE, ‘HH’)
By selecting the function above that matches your ETL frequency, you can successfully implement effective dating that reflects the change frequencies of your data as accurately as possible, even in an environment in which your source systems provide no definitive effective dates to pull from.