
I’ve had some fun working with StreamSets Data Collector lately and wanted to share how to quickly get up and running on an Amazon Web Services (AWS) Elastic Compute Cloud (EC2) instance and build a simple pipeline.
For anyone unaware, StreamSets Data Collector is, in their own words, a low-latency ingest infrastructure tool that lets you create continuous data ingest pipelines using a drag and drop UI within an integrated development environment (IDE).
To be able to follow along, it is encouraged that you have enough working knowledge of AWS to be able to create and start an AWS EC2 instance and create and access an AWS Simple Storage Service (S3) bucket. That being said, these instructions also apply, for the most part, to any linux installation.
The most important prequisite is to have access to an instance that meets StreamSets installation requirements outlined here. I’m running an AWS Red Hat Enterprise Linux (RHEL) t2.micro instance for this demo; you will no doubt want something with a little more horsepower if you intend to use your instance for true development.
It is important to note that this is just one of many ways to install and configure StreamSets Data Collector. Make sure to check out the StreamSets site and read through the documentation to determine which method will work best for your use case. Now that the basics (and a slew of acronyms) are covered, we can get started.
Fire up the AWS EC2 instance and log in. I’m running on a Mac and using the built in terminal; I recommend PuTTY or something similar for folks running Windows.
ssh ec2-user@<public_ip> -i <loc_of_pem>/<name_of_pem>.pem
Install wget, if you haven’t already.
sudo yum install wget
Create a new directory for the StreamSets download and navigate to the new directory
sudo mkdir /home/ec2-user/StreamSets cd /home/ec2-user/StreamSets
Download StreamSets Data Collector using wget. The URL below is for version 2.4.1 rpm install but a new version of Data Collector is likely out by the time this gets published (those guys and gals move quickly!). Be sure to check for the latest version on the StreamSets Data Collector website
Look for the download here:
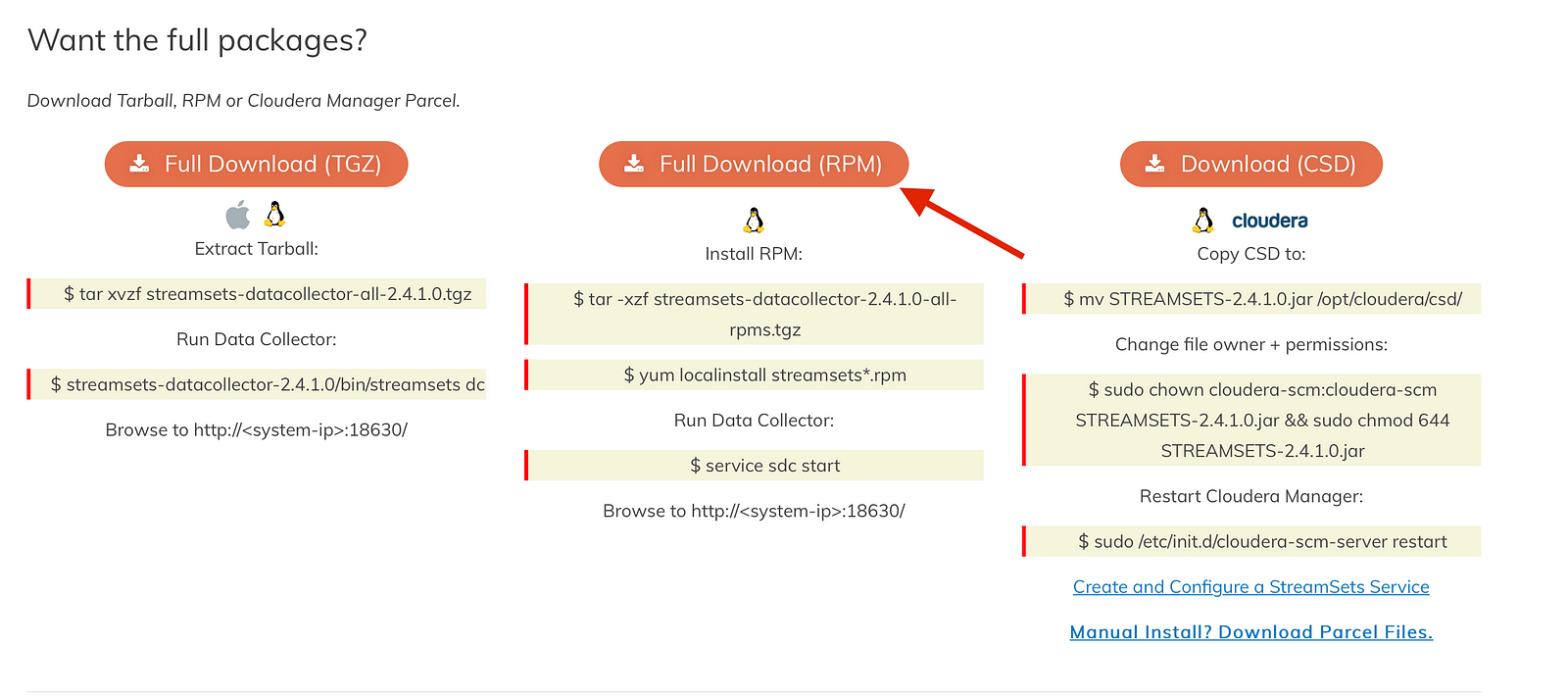
You’ll want to right click Full Download (RPM) and select ‘Copy Link’. Replace the link in the command below with the latest and greatest.
sudo wget https://archives.streamsets.com/datacollector/2.4.1.0/rpm/streamsets-datacollector-2.4.1.0-all-rpms.tgz
Extract the StreamSets Data Collector install files.
sudo tar -xzf /home/ec2-user/StreamSets/streamsets-datacollector-2.4.1.0-all-rpms.tgz
Install StreamSets using yum/localinstall
sudo yum localinstall /home/ec2-user/StreamSets/streamsets-datacollector-2.4.1.0-all-rpms/streamsets*
Attempting to start the service reveals there is one step remaining as the command fails.
sudo service sdc start
ERROR: sdc has died, see log in '/var/log/sdc'.
Note the File descriptors: 32768 line item in the installation requirements
Running ulimit -n shows 1024, this needs to be ≥32768
ulimit -n
1024
To increase the limit, edit /etc/security/limits.conf by navigating to /etc/security
cd /etc/security
As good habits dictate, make a copy of the limits.conf file
sudo cp limits.conf orig_limits.conf
Edit the limits.conf file
sudo vi limits.conf
Add the following two lines at the end of the file, setting the limits to a value greater than or equal to 32768
* hard nofile 33000 * soft nofile 33000
Log out of the AWS machine and log back in for the changes to take effect
Check that the changes were successful by running ulimit -n
ulimit -n
33000
Start the SDC service
sudo service sdc start
This message may show up:
Unit sdc.service could not be found.
The service will start fine. If you’re annoyed enough by the message, stop the service, run the command below, and start the service again
sudo systemctl daemon-reload
One last thing before we get to building a pipeline. Create a new subdirectory under the streamsets-datacollector directory to store a sample data file.
sudo mkdir /opt/streamsets-datacollector/SampleData
Create a sample file.
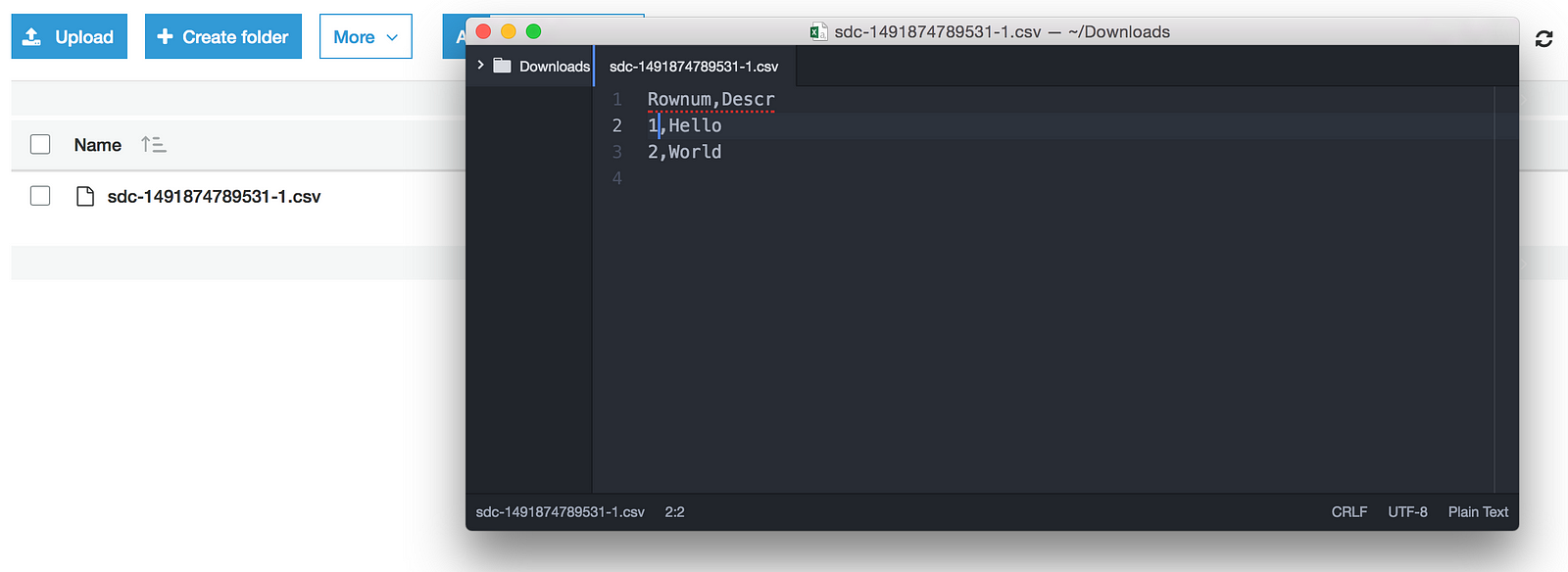
sudo vi /opt/streamsets-datacollector/SampleData/TestFile.csv
Enter the following records and save the file.
Rownum,Descr 1,Hello 2,World
The StreamSets Data Collector user interface (UI) is browser-based. In order to access the UI from your local machine, set up an SSH tunnel to forward port 18630, the port StreamSets runs on, to localhost:18630. Replace the appropriate IP address and .pem information.
ssh -N -p 22 ec2-user@<public_ip> -i <loc_of_pem>/<name_of_pem>.pem -L 18630:localhost:18630
On the local machine, open a browser, type or paste the following URL and press enter.
http://localhost:18630/
The StreamSets login page should now be displayed. The initial username/password are admin/admin.
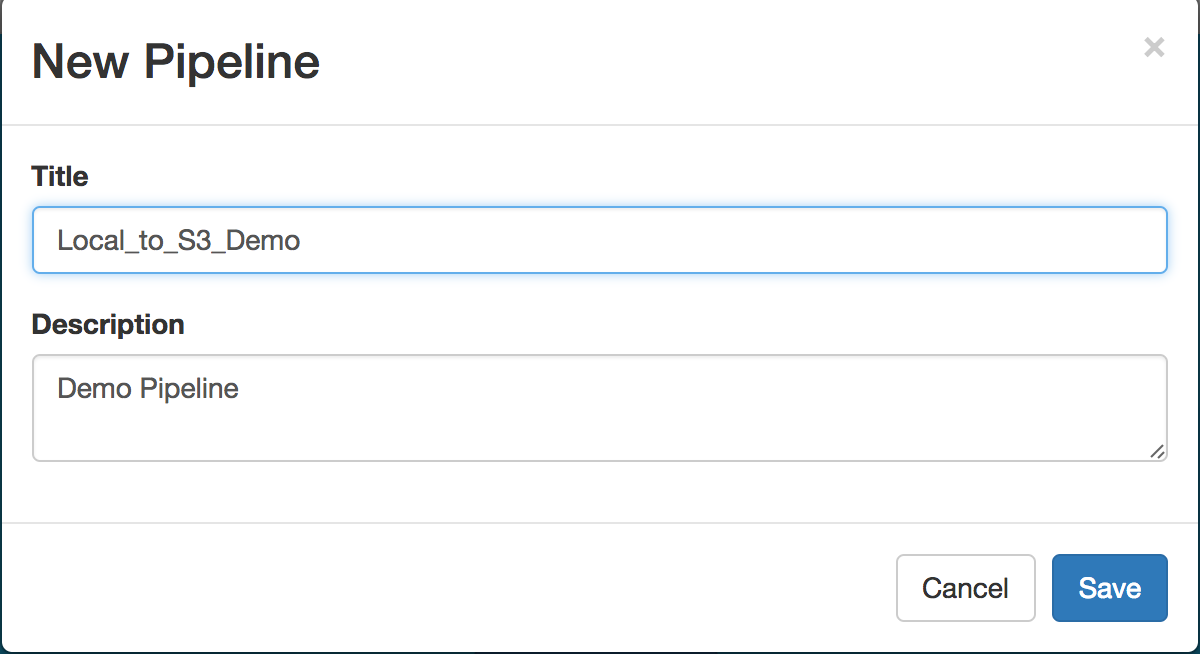
In the following steps, we’ll create a pipeline that streams the data from the TestFile.csv file created in the steps above to Amazon S3. First, create a new pipeline and give it a name.
Add an origin and a destination. For this example, I have selected the origin Directory — Basic and the destination Amazon S3 — Amazon Web Services 1.10.59
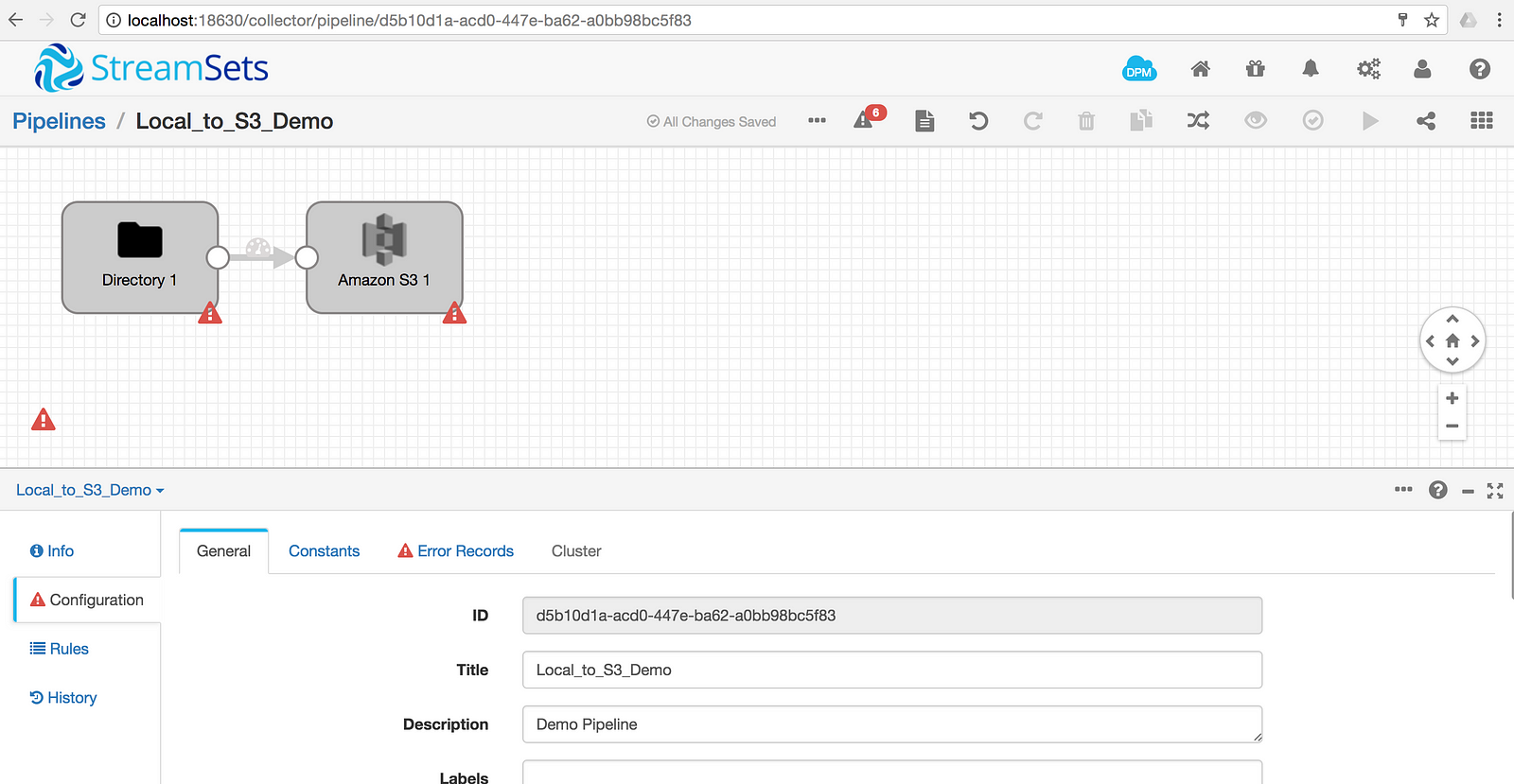
Notice that the pipeline will display errors until all required elements are configured.
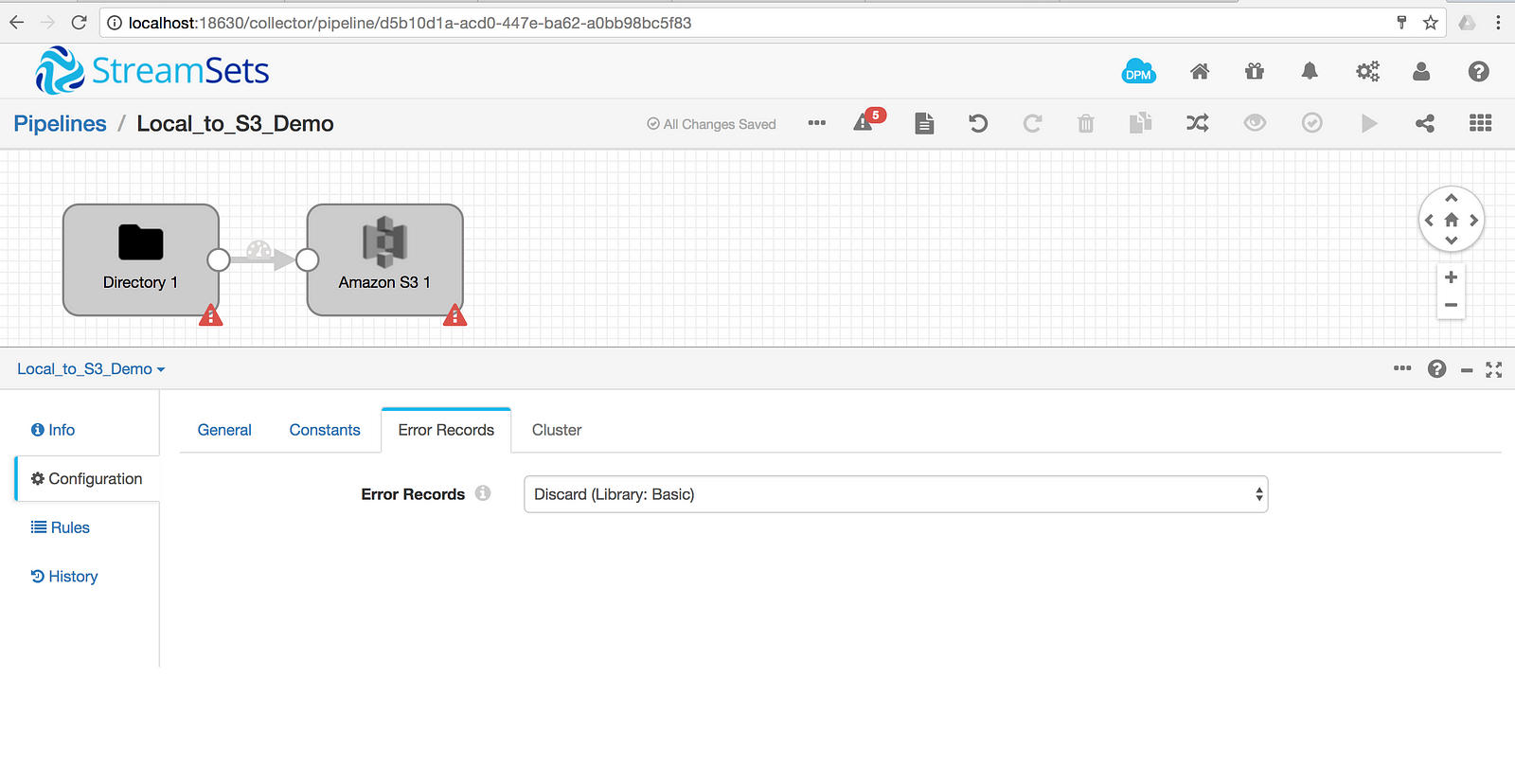
Configure the pipeline Error Records to Discard (Library: Basic)
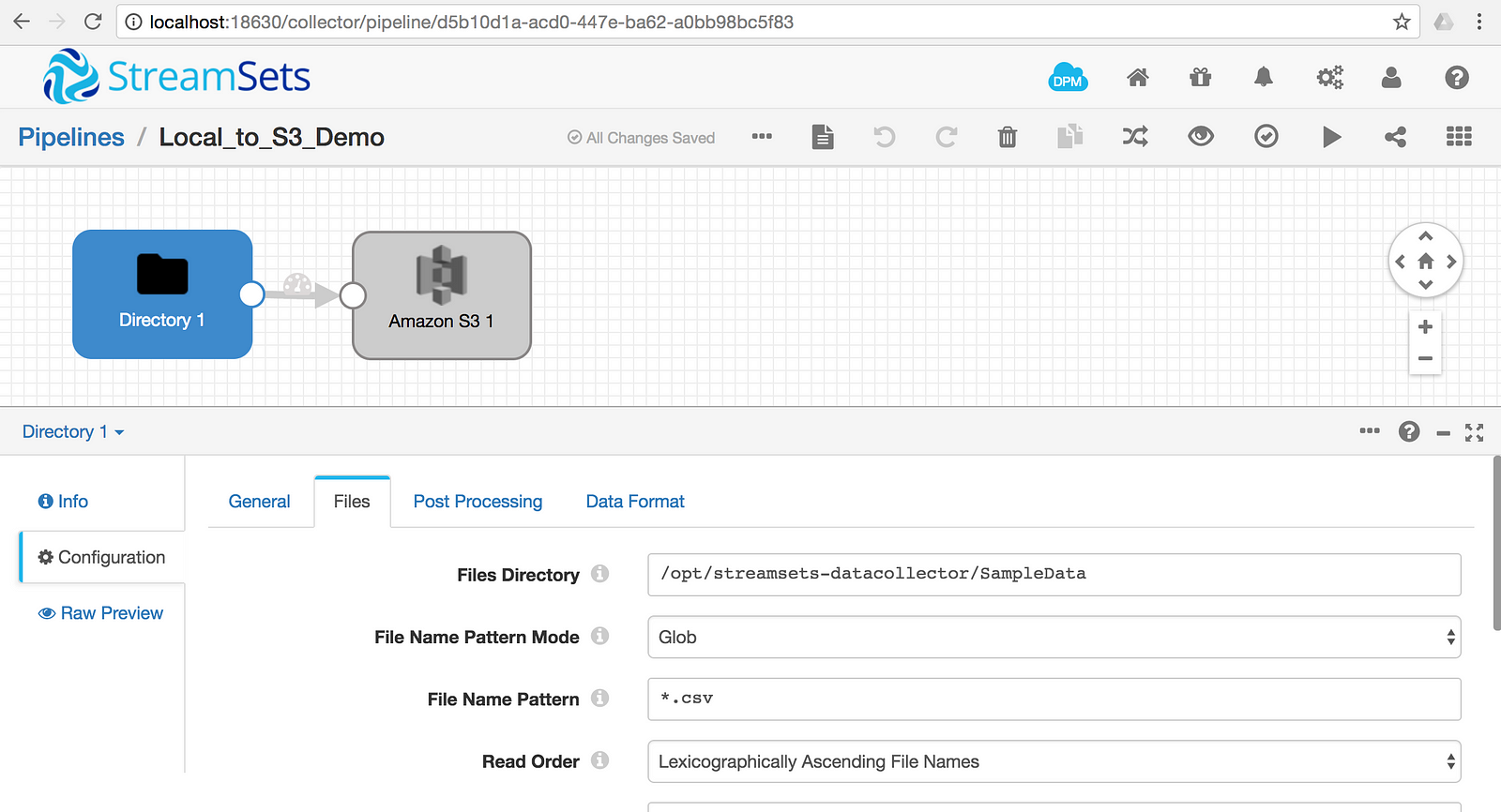
To set up the origin, under Files, configure the File Directory and File Name Pattern fields to /opt/streamsets-datacollector/SampleData and *.csv, respectively.
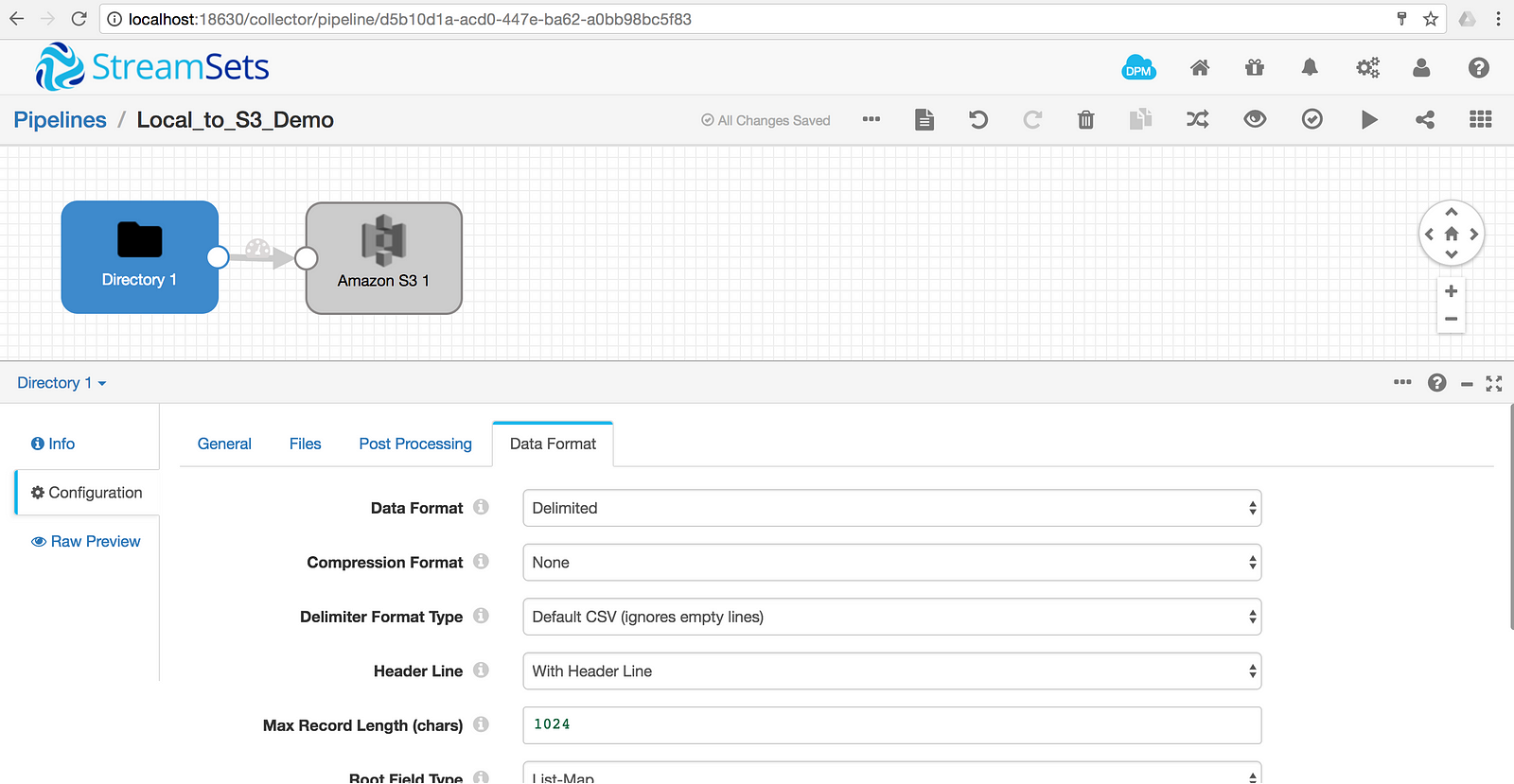
On the Data Format tab, configure the Data Format to Delimited and change the Header Line drop-down to With Header Line
Configure the Amazon S3 items for your Access Key ID, Secret Access Key, and Bucket.
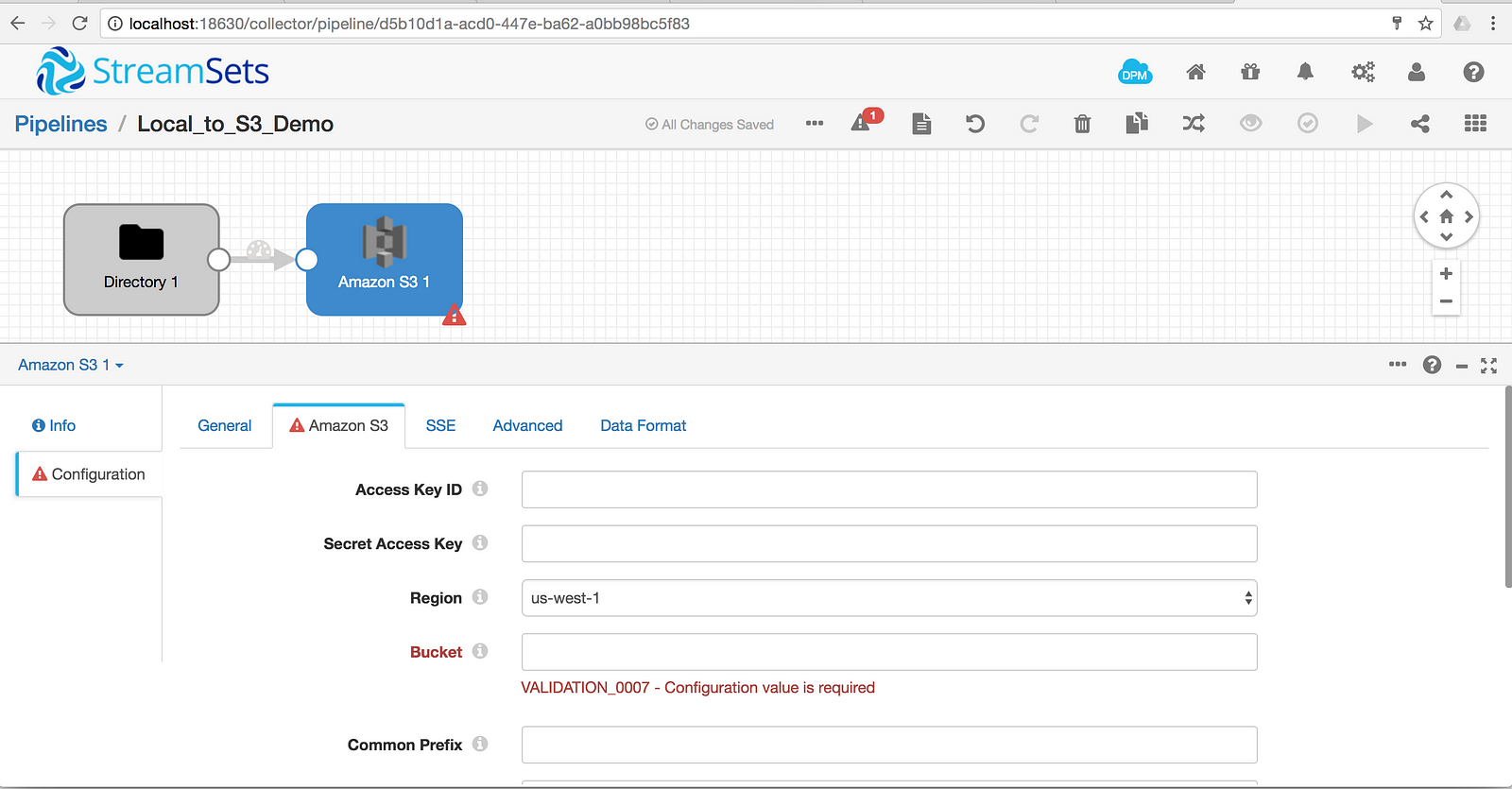
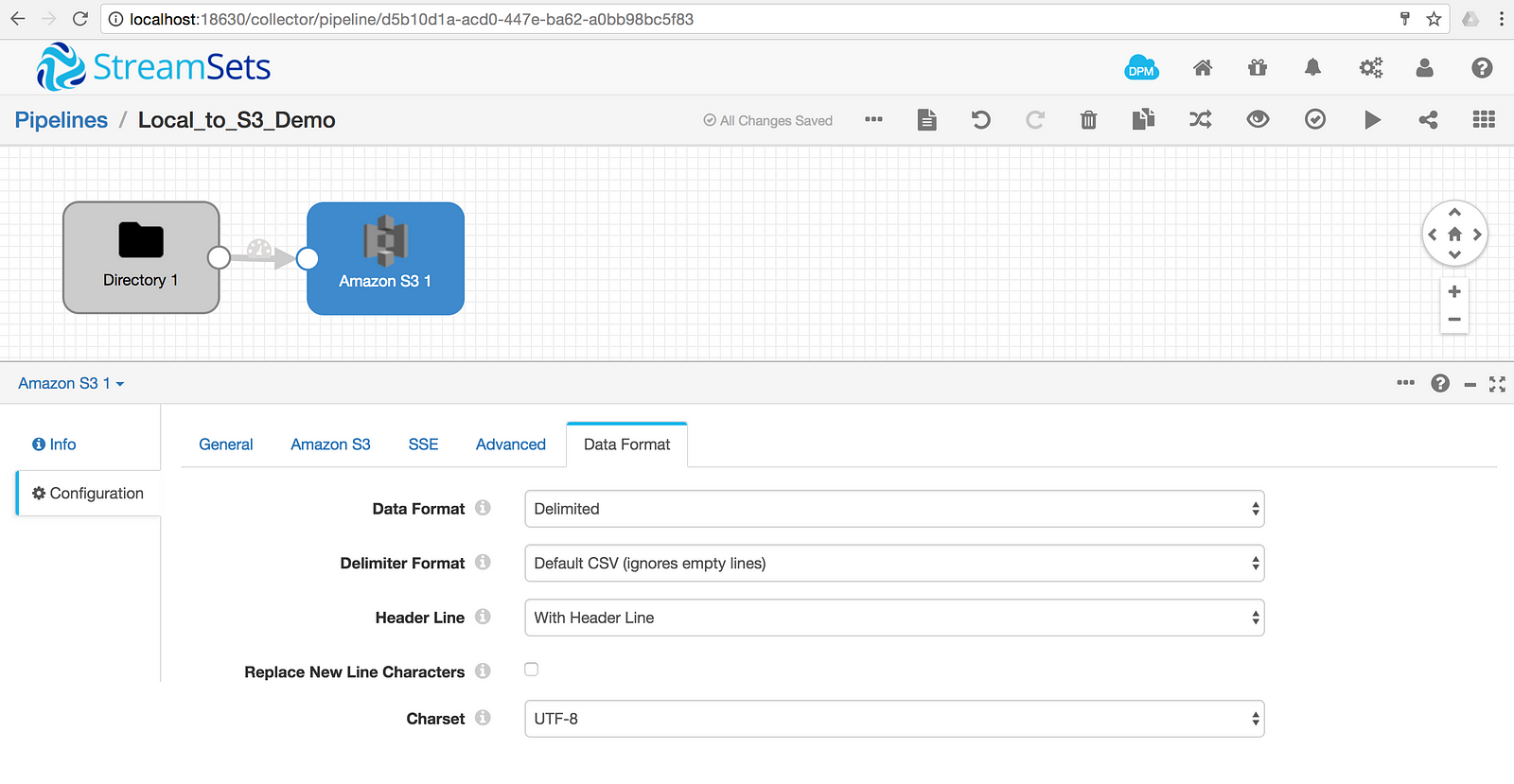
Set the Data Format for S3; I’ve chosen Delimited but other options work just fine.
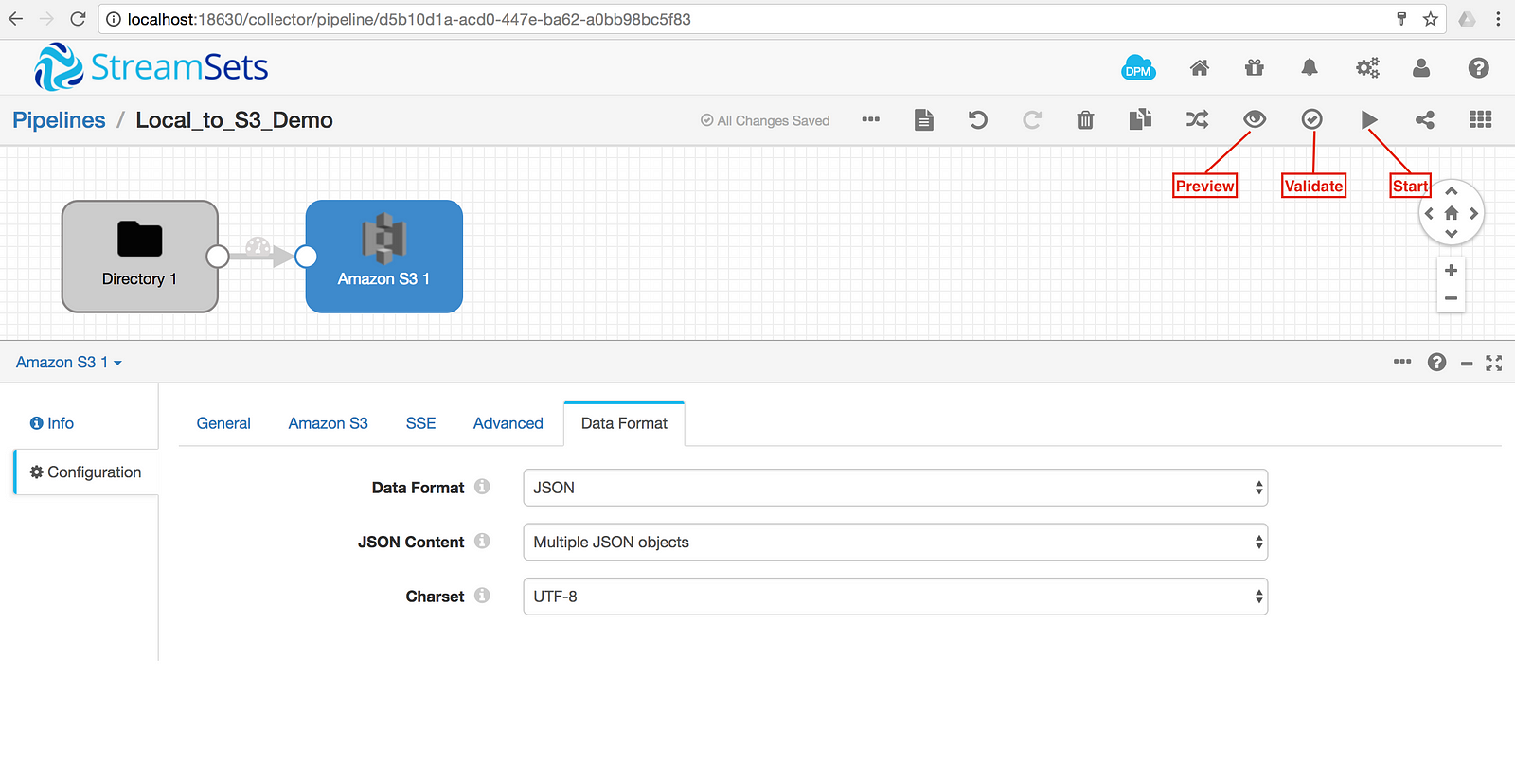
In the top right corner, there are options for previewing and validating the pipeline as well as to start the pipeline. After everything checks out, start the pipeline.
The pipeline is alive and moved the data!
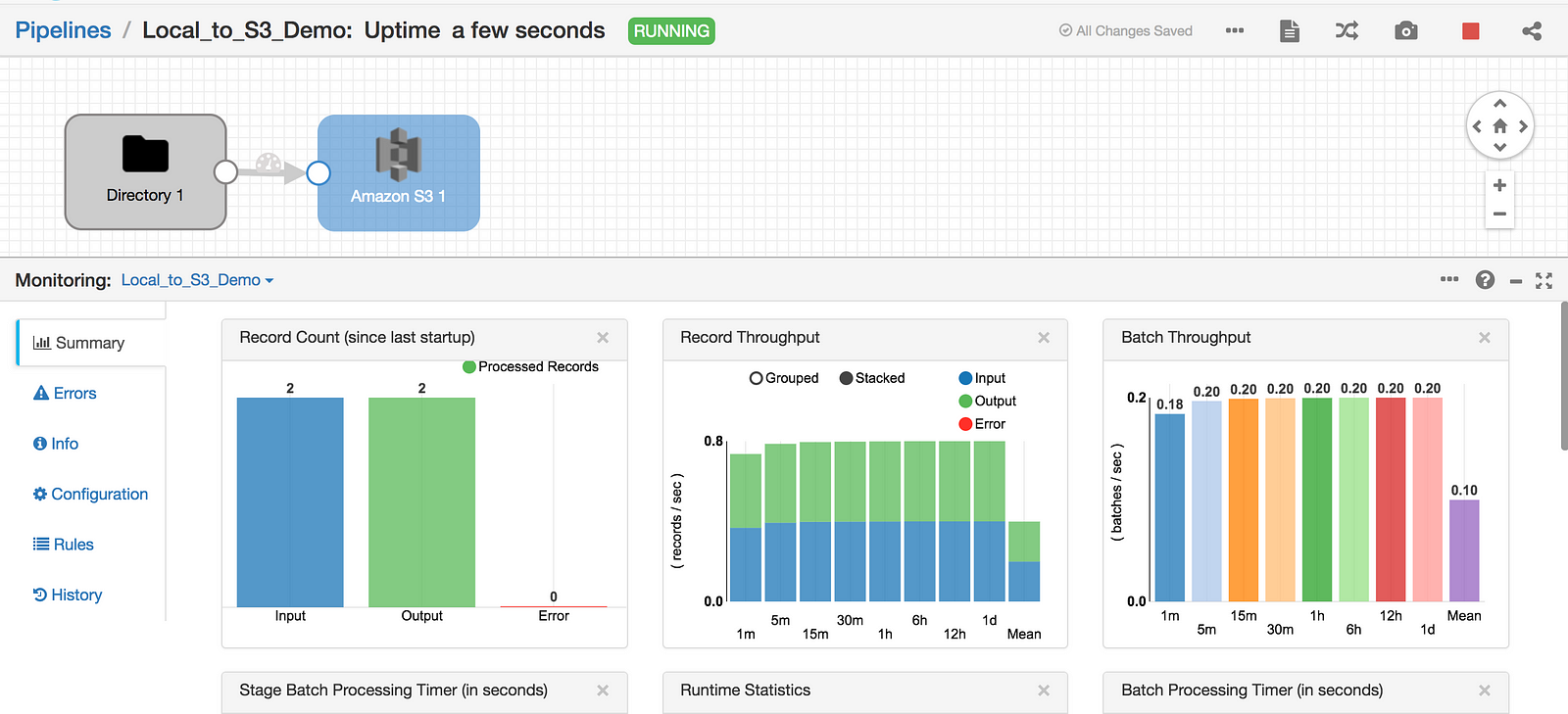
A review of S3 shows that the file has been created and contains the records that were created in the steps above. Notice that the pipeline is in ‘Running’ status and will continue to stream data from the directory as changes are made or *.csv files are added.
There you have it. This is just a basic pipeline to move a .csv file from one location to another without any data manipulation and is simply the tip of the iceberg. There is an abundance of options available to manipulate the data as well as technologies that StreamSets Data Collector integrates with that go far beyond this example. Happy streaming!

