
Whether it’s an enterprise application, the automobile you drive, or your favorite tea kettle, seemingly everything in the world today produces data. This results in a need to transfer data to a place where people and technology can make sense of it. Typically, the faster data can be transferred and more data that can be stored in a centralized location, the better. One method of speeding up the data transfer process is to avoid running multiple insert statements and complete load tasks en masse, a function commonly referred to as bulk loading. StreamSets Data Collector and Snowflake Data Warehouse have emerged as front-runners for transferring and storing data, respectively, and conveniently work well together when bulk loading data.
Bulk loading data into Snowflake Data Warehouse is achieved using two basic commands: PUT and COPY INTO. Think of it like this: put the data somewhere Snowflake can see it and copy the data into Snowflake; pretty straightforward. As is often the case, these two commands support several options and can be made to be more complex but at their core, it is as simple as it sounds.
So where can Snowflake see the data? Answer: in an internal stage (user, table, or named) or an external stage, which amounts to any AWS S3 Bucket that Snowflake is given access to. With an internal stage, SnowSQL or an equivalent client is used to upload files using the PUT command. Externally staged data files have a bit more freedom in that any technology that can ship files to S3 can be used. Enter StreamSets Data Collector.
StreamSets Data Collector (SDC) includes Amazon S3 as a destination (the PUT) and a JDBC Executor that can be called from the S3 destination using event framework, also called triggers, (the COPY INTO).
Focusing on externally staged data, the first step is to create an S3 bucket to be used for staging the data files. Red Pill Analytics already has a bucket for SDC prototyping in our account; that will do just fine.
Next, Snowflake needs access to read from the bucket; the following statement will create an external stage. Note: It is also possible to read straight from an S3 bucket without defining a stage. This particular statement creates a stage called streamsets_test in the rpa_demo.publicschema.
create stage rpa_demo.public.streamsets_test url = 's3://<bucket>' credentials = (aws_key_id = '<aws_key>' aws_secret_key = '<aws_secret_key>');
And then a table in the same database.schema to serve as the target. The pipeline will be configured to create JSON files so only one variant-type column is necessary:
create table rpa_demo.public.streamsets(v variant);
Lastly, a file format to facilitate loading JSON data rounds out the Snowflake setup:
create file format rpa_demo.public.json type = 'JSON' compression = 'auto';
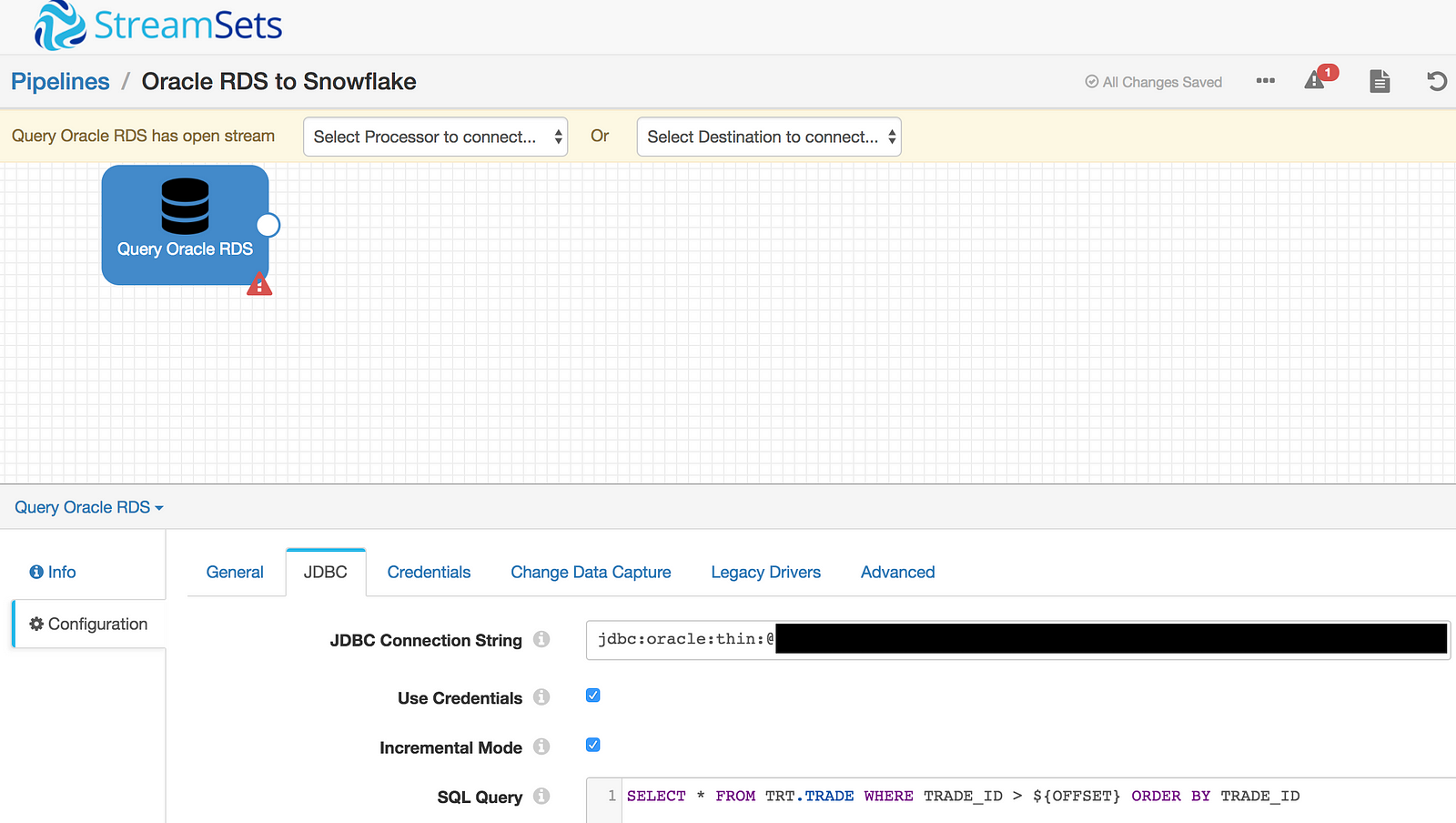
Now to configure the SDC pipeline. The source can be any origin that StreamSets supports. I’ve recently been working on an Oracle RDS database that contains TPC-DI data so I’ll run with that for now by using the JDBC Query Consumer. Important: To connect to a database via JDBC, the appropriate JDBC driver needs to exist or be added to the SDC external libraries. This remains true for loading data to Snowflake Data Warehouse.
A JDBC connection string and simple query using SDC syntax for incremental mode (if required) are all that is needed for this stage. This example will query data in the TRADE table:
Any of the SDC processors can be used to perform additional data processing at this point but rather than adding complexity, going straight from source to target will help keep it simple. With that said, the next step is to add the Amazon S3 destination using the same bucket that was created as a Snowflake external stage. The S3 destination needs a bucket name and its corresponding keys:
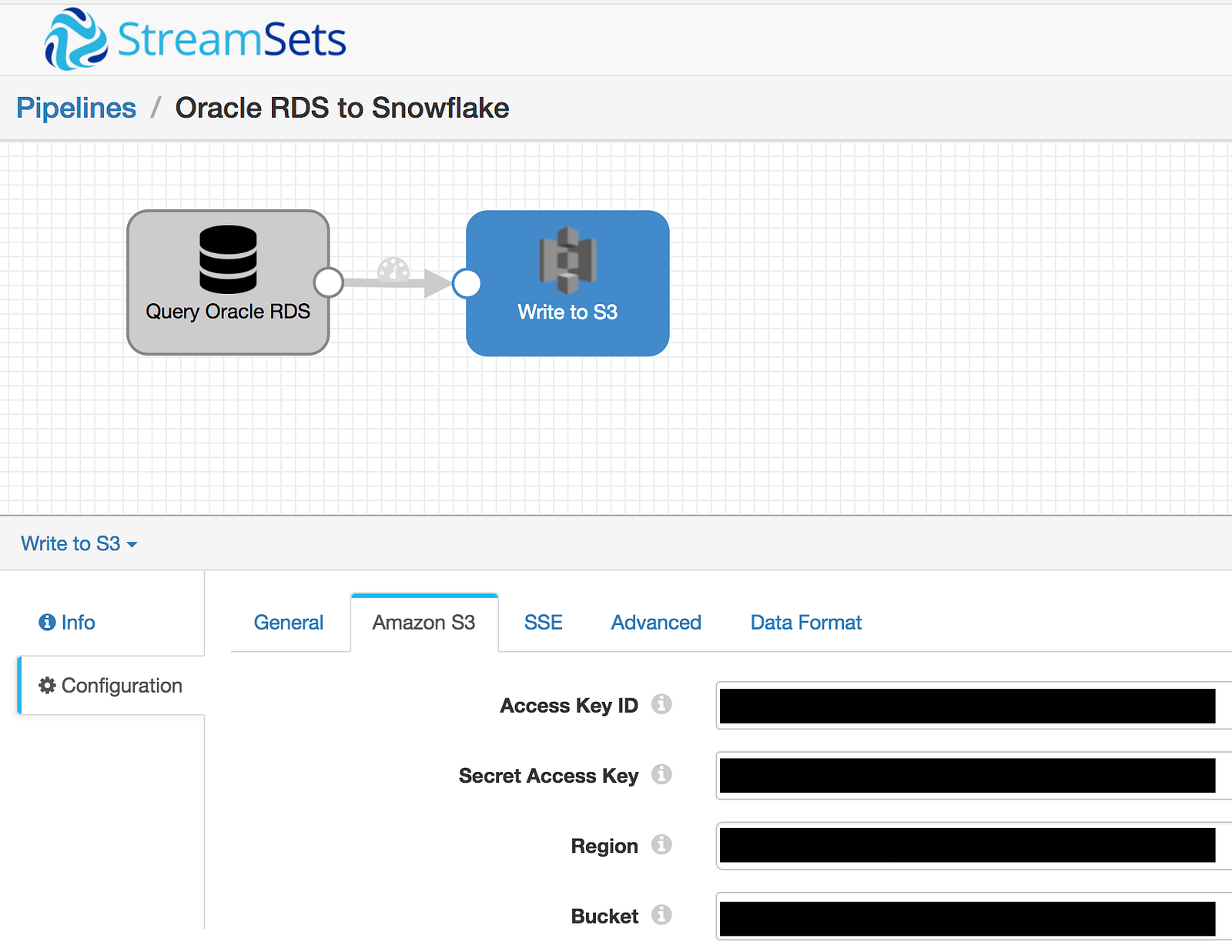
Triggers are enabled by simply checking the box labeled Produce Events on the S3 destination:

The JDBC Executor is now able to be called after data files are written to S3. By placing the SQL statement below in the JDBC Executor SQL Queryconfiguration, only the statement (not the data) will be issued to Snowflake via a JDBC call. Snowflake will then handle the connection back to the S3 bucket based on the setup/configurations above and bulk load the data into the specified destination; in this case,rpa_demo.public.streamsets.
copy into rpa_demo.public.streamsets from @streamsets_test file_format = 'json';
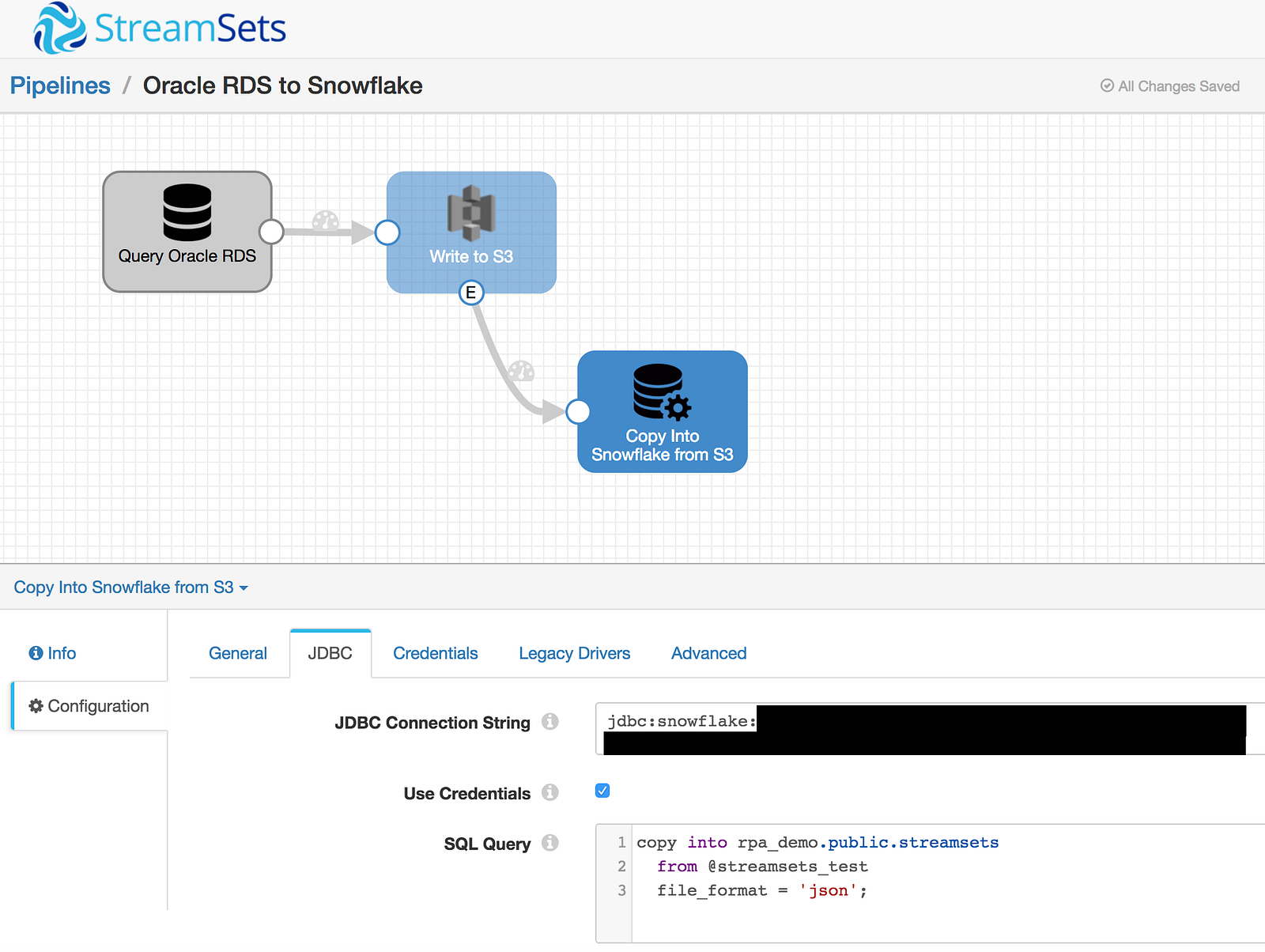
The pipeline is ready to go. On your mark, get set, start the pipeline! As expected, SDC has created a .json file in S3…
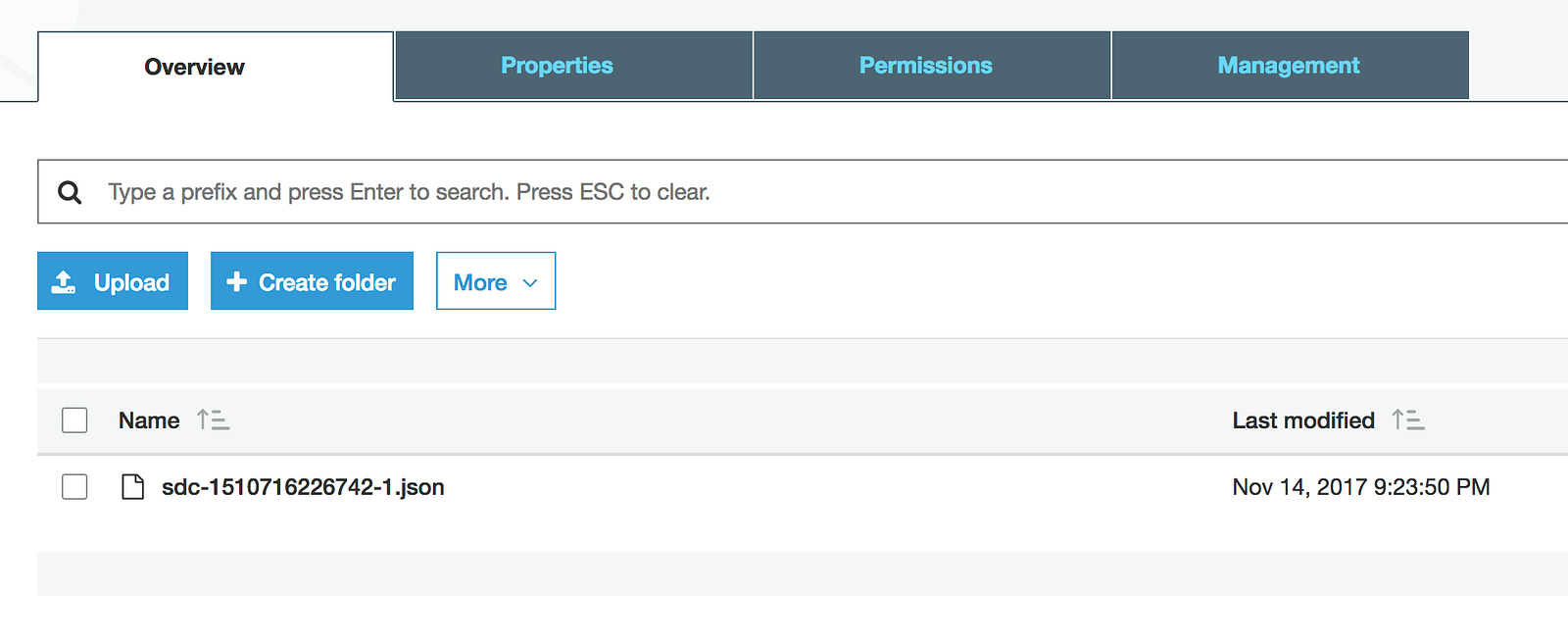
…and the data has been copied into Snowflake.

Success!
As an aside — SDC also provides a JDBC Producer destination which can be used to load Snowflake and is sufficient in many, usually smaller scale, use cases. The JDBC Producer loads records using insert statements with bind variables; use PUT/COPY INTO when bulk loading is desirable.
Be sure to check back for follow-up blogs on how to enhance the basic process outlined in this post.