
Package Delivered: Accelerate Your DBT Project Initialization
Anyone who has worked with dbt knows that one of the most powerful features is packages. Packages allow you to reuse code across multiple projects in an organization. Packages can be installed from other projects in your organization, or by using the dbt hub you can install packages from the open-source community and Fishtown Analytics. I am going to illustrate the power of these by focusing on one macro in a package called codegen from dbt. This package that has some “accelerators” in it to help new project implementations generate base code. The macro in this package I want to highlight is called generate_source, which helps generate source.yml files. Sources are any object that will be used in a dbt project but do not contain code that will be maintained in the dbt project. These source definitions go in a YAML file called sources.yml.
After installing the package, you just need to invoke the macro, which I did via a run operation and passing the parameters of the schema I want to generate my sources from and whether or not I want it to give me the list of columns in that source.
run-operation generate_source — args ‘{“schema_name”: “edw_common_etl”, “generate_columns”: “True”}’
This macro queries the information schema in the database to compile the list of objects from that schema to be used as a source. The nice thing about this macro is that by default it outputs all the objects in that schema in the correct format for the source.yml file.
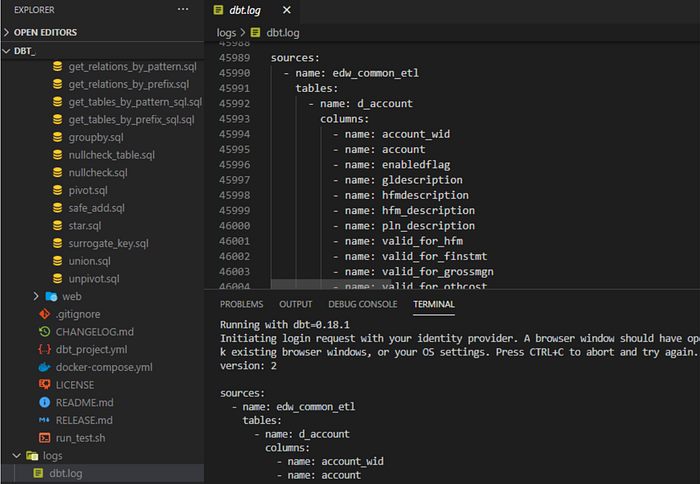
I can hear you asking yourself right now, what if I don’t want to import all the objects in a schema? What if that schema contains a mix of objects that will be sources and models? Sorry, by default it does not allow you to pick specific sources, it assumes you have schemas that contain only sources. So that is a problem with this macro…or at least it would be if it were a traditional ETL tool. Since these macros are just code, you can edit it!
I recently ran into this issue while implementing dbt on a semi-mature enterprise data warehouse in Snowflake. This environment has a multi-schema architecture with different data layers, while also segregating the data based on its functional contents, such as common dimensions, revenue, people, etc. All of this is to say that our transformations are built using sources that can be in different schemas, which are intermixed with tables and views that will become dbt models. Because of this, it makes the default behavior of the macro not very valuable as I would have to do a lot of editing to remove “sources” that will actually become models. Fortunately, there is a custom control table in this data warehouse that stores a list of all the views that are used as sources, so I just started tracing the code to see how I could modify the macro.
I am pretty novice when it comes to Jinja, so fortunately it is a pretty easy language to parse and in this case, I didn’t have to modify any Jinja, just SQL. I started with the top level macro and kept tracing until I found something that looked like a query to the information schema.

After looking in the get_relations_by_prefix_sql macro, which uses get_tables_by_pattern_sql, I found what I was looking for. Line 10 contained the original source of the query, so to make things easy I created a new view called dbt_source_gen in the edw_admin schema of our data warehouse, which is essentially select * from information_schema.tables inner join custom_control_table then just replace the from clause in the macro.
{% macro get_tables_by_pattern_sql(schema_pattern, table_pattern, exclude='', database=target.database) %}
{{ adapter.dispatch('get_tables_by_pattern_sql', packages = dbt_utils._get_utils_namespaces())
(schema_pattern, table_pattern, exclude, database) }}
{% endmacro %}
{% macro default__get_tables_by_pattern_sql(schema_pattern, table_pattern, exclude='', database=target.database) %}
select distinct
table_schema as "table_schema", table_name as "table_name"
{# from {{database}}.information_schema.tables #}
from {{database}}.edw_admin.dbt_source_gen
where table_schema ilike '{{ schema_pattern }}'
and table_name ilike '{{ table_pattern }}'
and table_name not ilike '{{ exclude }}'
{% endmacro %}
{% macro bigquery__get_tables_by_pattern_sql(schema_pattern, table_pattern, exclude='', database=target.database) %}
{% if '%' in schema_pattern %}
{% set schemata=dbt_utils._bigquery__get_matching_schemata(schema_pattern, database) %}
{% else %}
{% set schemata=[schema_pattern] %}
{% endif %}
{% set sql %}
{% for schema in schemata %}
select distinct
table_schema, table_name
from {{ adapter.quote(database) }}.{{ schema }}.INFORMATION_SCHEMA.TABLES
where lower(table_name) like lower ('{{ table_pattern }}')
and lower(table_name) not like lower ('{{ exclude }}')
{% if not loop.last %} union all {% endif %}
{% endfor %}
{% endset %}
{{ return(sql) }}
{% endmacro %}
{% macro _bigquery__get_matching_schemata(schema_pattern, database) %}
{% if execute %}
{% set sql %}
select schema_name from {{ adapter.quote(database) }}.INFORMATION_SCHEMA.SCHEMATA
where lower(schema_name) like lower('{{ schema_pattern }}')
{% endset %}
{% set results=run_query(sql) %}
{% set schemata=results.columns['schema_name'].values() %}
{{ return(schemata) }}
{% else %}
{{ return([]) }}
{% endif %}
{% endmacro %}
In about 30 minutes I went from thinking this helps but may not save all that much time, to this is fantastic and I can now generate all of my source.yml files and not have to worry about editing out non-sources.
A further idea I had for editing this macro would be to insert a new step before line 52 that lists the key on the table and adds the schema tests we perform on all sources to that column. Unfortunately, Snowflake doesn’t make it easy to compile a list of primary keys on tables, and views have no keys. So perhaps I may need to create a Snowflake procedure or dbt macro to process the table DDL and create a table listing out the keys to be used for running schema tests. Being able to add that customization would make this macro be able to be run not just for initializing the project, but could be used to refresh column lists on sources at any time. This macro can be easily modified as well to just return a single table or view instead of the whole schema to make it easy to add new sources to an existing sources.yml file.

I found this to be a particularly powerful example of the benefits of using an open-source, code-based platform that allows you to take code and think of it as a starting point and be able to customize it for your own unique situation.
Is your organization adapting to remain competitive? In the Architect Room, we design a roadmap for the future of your digital organization, while still capitalizing on current technology investments. Our knowledge spans a variety of offerings across all of the major public cloud providers. Visit Red Pill Analytics or feel free to reach out on Twitter, Facebook, and LinkedIn.
21 Responses to Package Delivered: Accelerate Your DBT Project Initialization